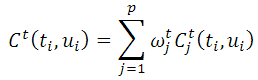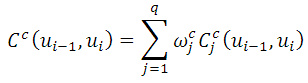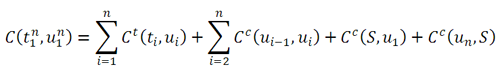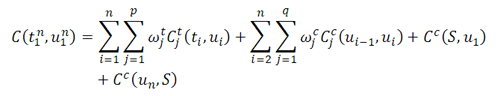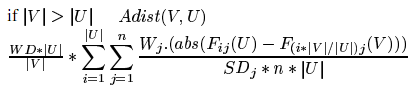Синтез русской речи по тексту Существует несколько подходов к организации автоматического синтеза речи по тексту. К основным можно отнести синтез по правилам (формантный синтез), артикуляторный синтез, компилятивный синтез, синтез на основании статистических моделей (HMM-синтез). До последнего времени наиболее распространенной технологией синтеза являлся компилятивный аллофонный (или дифонный) синтез. Однако на данный момент наилучшие результаты достигаются с использованием другой разновидности компилятивного синтеза – технологии Unit Selection. Данная технология позволяет достичь максимальной естественности синтезированной речи. Синтез на основании статистических моделей хоть и является наиболее молодым и весьма активно развивающимся подходом, по качеству значительно уступает Unit Selection, основанному на корректно отсегментированной на разных уровнях речевой базе данных большого объема.
Анализ публикаций и существующих систем синтеза речи для разных языков позволяет утверждать, что технология Unit Selection является наиболее перспективной в плане достижения максимальной естественности синтезированной речи. Стоит отметить, что на настоящий момент не существует разработанных в России полноценных реализаций данной технологии для синтеза русской речи. Как следствие, в рамках работы по созданию новой системы синтеза русской речи, осуществляемой ООО «Центр речевых технологий», в основу системы было решено положить технологию Unit Selection, совместив ее с аллофонным синтезом.
Метод Unit Selection.
Основы. Классический подходДля создания естественно звучащей речи по полученной на ранних этапах работы синтезатора фонетико-просодической последовательности подбираются наиболее подходящие элементы из большой речевой базы. Для того чтобы определить, насколько тот или иной элемент базы подходит для синтеза данной единицы, вводятся понятия стоимости замены (англ. target cost) и стоимости связи (англ. concatenation cost). Стоимость замены для элемента из базы по отношению к искомому элементу вычисляется по формуле
Другими словами, это есть взвешенная сумма различий в признаках между требуемым элементом и конкретным элементом речевой базы. В качестве признаков могут выступать любые уместные, с точки зрения разработчика, просодические и лингвистические характеристики элементов. Как правило, используется следующая информация: частота основного тона (ЧОТ), длительность, контекст, позиция элемента в слоге, слове, количество ударных слогов во фразе и другие.
Выбранные элементы должны не только мало отличаться от целевых, но и хорошо соединяться друг с другом. Функция стоимости связи двух элементов может быть определена как взвешенная сумма различий в признаках между двумя последовательно выбранными элементами
Общая стоимость для целой последовательности из n элементов есть сумма введенных выше стоимостей
Задача US — выбрать такое множество U1,U2,...Un которое бы минимизировало общую стоимость согласно формуле (3).
Стоимость заменыОсновное назначение функции стоимости замены — оценивать, в какой мере подходит данная единица речевой базы к требуемому элементу. В связи с этим, стоимость замены должна отражать, как сильно различия в характеристиках влияют на восприятие замены одного элемента другим. При построении этой функции, как правило, руководствуются одним из следующих принципов: независимых признаков и акустического пространства.
Принцип независимых признаков.В этом случае расстояние для каждого признака считается независимо от других, взвешивается и затем общая стоимость считается как некоторая функция полученных расстояний. В качестве такой функции можно использовать простую сумму (1). Функции определяют расстояния для каждой отдельно взятой характеристики. Для категориальных это может быть простое бинарное решение, совпадают они или нет. Для непрерывных (например, ЧОТ) это может абсолютное расстояние или его логарифм. Различия в одних характеристиках оказывают больше влияния на восприятие замены, чем в других. Эта разница отражается в выборе весов для конкретного расстояния. Для установки весов существует несколько подходов: автоматический подбор на основе объективной меры, перцепционный, ручная настройка.
Автоматический подбор на основе объективной меры. Суть этого подхода заключается в попытке найти такой набор весов, который минимизировал бы акустическое расстояние между синтезированным и эталонным выражениями. Для оценки близости требуется метрика, поставляющая расстояния между синтезированными и эталонными высказываниями. Высказывания, воспринимаемые на слух как сходные, должны иметь маленькое расстояние между собой. Для нахождения оптимальных весов достаточно воспользоваться методом линейной регрессии. Задача определения такой метрики является отдельной проблемой. При таком подходе веса могут подбираться индивидуально для каждой единицы базового типа.
Перцепционный. Слабое место предыдущего подхода заключается в том, что разработчик во многом полагается на акустическую меру, которая лишь частично соответствует человеческому восприятию. В рамках данного подхода ставится эксперимент, в котором людей просят оценить синтезированные предложения, а затем тренируют модель согласно полученным оценкам. Очевидный недостаток — большие временные затраты и сложность в организации эксперимента.
Ручная настройка. Проектировщик системы полностью полагается на свой опыт. В ходе тестирования системы веса постепенно уточняются. Главное преимущество - полный контроль над процессом.
Очевидным плюсом принципа независимых признаков при построении функции стоимости замены является небольшое число подлежащих настройке весов (равное количеству используемых признаков). Однако предположение независимого влияния весов на общую стоимость является слишком сильным. Яркой демонстрацией слабости этого принципа является тот факт, что два различных набора характеристик будут неминуемо иметь ненулевое расстояние. Это противоречит нашим знаниям о речи, которые как раз говорят о том, что различные комбинации характеристик зачастую проецируются в одну акустическую реализацию.
Принцип акустического пространства.Главная идея этого подхода заключается в кластеризации единиц базового типа по просодическому и фонетическому контекстам. Блэк и Тэйлор предложили следующую схему кластеризации.
Вводится объективная мера для измерения расстояний между единицами одного базового типа. Опять же, выбор подходящей акустической меры — отдельное поле для исследований. В своей работе авторы используют взвешенное расстояние Махаланобиса на коэффициентах MFCC (Mel Frequency Cepstral Coefficients) , ЧОТ, мощности и их дельтах (производных первого порядка). Акустическое расстояние между двумя единицами — это среднее по всем фреймам внутри единиц плюс среднее по X% фреймов единиц, предшествующих рассматриваемым (близкие единицы будут иметь сходный левый контекст):
где U,V — элементы одного базового класса,
|U|<|V| — количество фреймов в U и V,
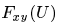
- признак y фрейма x элемента U,
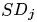
- стандартное отклонение признака j,
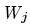
- вес для признака j ,
WD - взвешивает разницу в продолжительности элементов.
Введенная мера используется для вычисления «загрязненности» кластера C как среднего акустического расстояния между элементами кластера.
Затем с помощью стандартной техники деревьев решений кластер разбивается на две части наилучшим образом.
В качестве критерия разбиения используются бинарные вопросы, которые касаются характеристик, применяемых для вычисления стоимости замены (фонетический контекст, просодический контекст (ЧОТ и длительность для элемента и его соседей), ударение, позиция в слоге, позиция в слове, позиция в предложении). На каждом этапе выбирается вопрос, дающий лучшее разбиение. Разбиение обычно продолжается до тех пор, пока не будет достигнут какой-либо порог (например, минимальное количество элементов в листе).