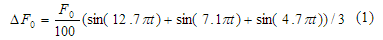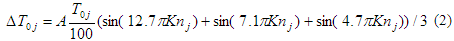Abstract In this paper the strategy and ways of F0 contour generation in TTS system for Russian language are described. The system is developed in Lomonosov Moscow State University and based on two methods: concatenation of allophones' waveforms and prosodic rules to control pitch, duration and intensity. These rules form a part of speech control module which carries out the interface function, bridging the gap between the output of text linguistic processing and the input of speech signal generation module. As a result each segment (allophone) in a phrase being synthesized is attributed by at least two F0 values as its starting and ending points. Three and even more F0 values can be assigned to the phone if it is necessary.
Signal generation is implemented according to the phrase control file, which describes the phrase as a sequence of allophones code names with assigned duration, energy and fundamental frequency values. To transform the base allophones to required prosodic values we use procedures that are close to TD PSOLA technology. All steps in development F0 modification algorithm based on TD-PSOLA technology are described and additional attention is paid to the ways of increasing naturalness of synthesized speech.
Overall architecture of the system The overall structure of our system is in line with the functional organization of a general TTS synthesizer. It consists of several blocks or modules, each of which has its own tasks and functions (Krivnova 1998). The structure of the system is shown on Fig.1.
Generation of pitch contour The basic unit, for which the pitch contour is generated, is an intonational phrase (IP) - a coherent, grammatically organized fragment of a text to which one intonational model (abstract tune) is attributed. The type of intonational model for IP gets out as a result of the work of accent-intonation transcriptor and is fixed as an abstract prosodic marker.
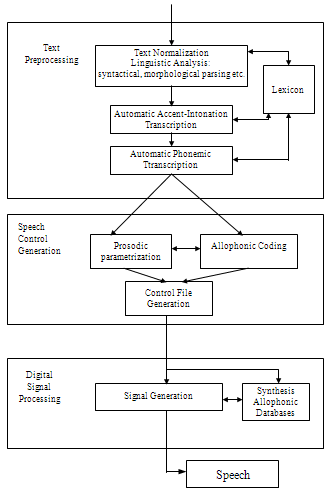
Figure 1. Overall structure of TTS system for Russian
This device also determines the levels of words' prominence that is important to generate naturally sounding pitch contours. We assume that rhythm and accentuation is adjusted by two functionally different mechanisms: focus accentuation and rhythmization. The focus accents (to contrast or emphasize some words) are substantially de-fined by a speaker intention or by the whole information structure of a text. Frequently this structure has no evident cues to determine an accent place and type. Therefore the formalization of focus accentuation represents the most difficult problem for TTS-systems. Our synthesizer is able to synthesize phrases with different focus accents but we have no rules to determine their localization automatically: it should be done manually. If a phrase has words with accent markers, the last of them is considered as the intonational center (nuclear) of a phrase. Otherwise the last content word of a phrase is as its intonational nuclear by default. It is the most typical situation for the narrative Russian texts, which construction is based on the use of neutral linear - accent structures with a final position of the intonational center.
As far as rhythmization is concerned, we distinguish three degrees of vowel prominence within a word (stressed, strong unstressed, weak unstressed) and four degrees for lexically stressed vowels (1 for full clitics, 2 for functional words, 3 for nonnuclear content words, 4 for nuclear content word). It should be noted that in Russian the prominence markers are very important not only for adequate pitch generation but also to determine correctly the duration of sounds.
In our system we use 7 abstract intonational models: 1 model of finality; 1 - non-finality; 3 - interrogative models (general, special, comparative questions); 1 - exclamation (or command). For all models the possibility of a different position of the intonational center is taken into account. The formation of F0 contours for concrete phrases within the same intonational model is carried out in the separate submodules.
The strategy of pitch generation in each intonational submodule is as follows. The contour of the synthesized IP is formed as a result of concatenation of two types of tonal objects - tonal accents the main of which are nuclear and tonal plateaus. Each intonational model is considered as a cluster of these tonal events with the possibility of various phonetic realization determined by the rhythmical and sound structure of the IP.
Tonal accents are aligned with lexically stressed syllables if their prominence level is not less than 3 and if they are not considered atonic in the chosen intonational model. The main control parameters for pitch accents are a type of pitch movement (tonal figure), the realization time domain (part of a phrase to which the accent is phonetically anchored, stressed syllable including), the localization of pitch target points of the accent in a speaker pitch range and in realization time do-main. We recognize that in Russian pitch movements forming the accent (and their targets) are very closely correlated with the boundaries of sound segments.
The tonal plateaus are aligned with unstressed and atonal stressed syllables in the beginning and end of IP and also in the intervals between pitch accent realization domains. The controllable parameters in this case are pitch values at the margins of intonational phrases and an interval of pitch change.
The temporal alignment and amplitude of tonal events are controlled by rules taking into ac-count the intonation model itself, the rhythmical pattern of IP and its segmental make-up. To make it possible the preliminary coding of syllables is carried out which fixes such features as accent status of a syllable, its prominence level (according to IP rhythmical structure), position in the IP and sound make-up. All pitch rules are hand-written and based on phonetic and acoustic analysis of read-aloud texts.
The calculation of F0 curves is implemented in two steps: at first in a semi-tone scale with respect to the average pitch (reference line) of a speaker, then these values are transformed into Hz. The calculated curve settles down in a working area of the speaker voice range, the boundaries of which are typical for realizations of the chosen intonational model.
Prosody modification algorithm for Russian TTSOne of the approaches in the creation of the high quality TTS system is the concatenative approach. Formation of the synthesized speech signal occurs in this case by means of connection of the acoustic waveform samples which are called elements of concatenation. The elements of concatenation are formed from the initial samples of the speech signal, storing in the database, by means of modification of their prosodic characteristics (such as duration, fundamental frequency and energy) in accordance with the requirements of the natural language processing module.
The theoretical foundation for the developing our methods of forming the prosodic characteristics of speech signal is TD-PSOLA approach. The main idea of TD-PSOLA methods consists in the following: the initial allophone is multiplied by sequence of time windows synchronized with fundamental frequency. The received sequence of acoustic segments, which are preliminary shifted about each other, is summed up, thus making the required modified allophone. To change the duration of the allophone the technology of repetition or elimination of some acoustic segments is used. In the traditional realization of this algorithm, in case of noticeable increase of the duration of speech signal, and caused by this many-timed repetition of some identical segments, a particular unnaturalness is observed in perception of the resultant speech. To make the phonation more natural we have built special algorithms based on random repetition and making some changes in the sequence of the identical acoustic segments. These algorithms are realized in the module P2 (Fig.2)
In our Russian speech synthesis system base elements of concatenation, in the majority of cases, have the phonemic measurement and, thus, are allophonic realizations of the traditional phonemes. The structure of module that is modifying prosodic characteristic of the vocal allophones is given in the Fig 2. (In our report we are not discussing the prosody modification algorithm for unvocal allophones (in this case only duration and energy is needed to be changed) because this particular part is not such complicated as for vocal allophones methods.)
One of the main requirements which essentially increase quality of the synthesized speech is minimization of the distortions in acoustic characteristics of the transitional parts of the allophone. Within the framework of this requirement the modification of the fundamental frequency is realized along the whole length of the initial allophone; alteration the duration of the allophone occurs only on its specially calculated parts – that is called stationary section. The calculation of the stationary parts can be accomplished on the stage of speech database creation thus increasing the speed of whole system. But in our system it is performing in digital signal processing module, because only in this stage of speech synthesis it is known to what degree initial allophone has to be changed and thus giving the possibility to estimate the length of the stationary part.
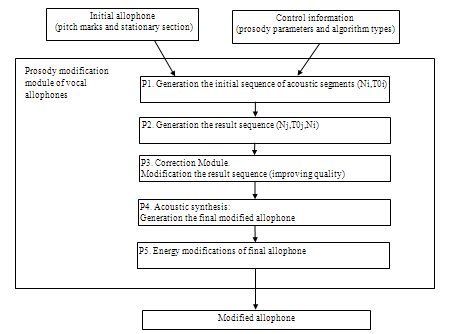
Figure 2. The structure of prosody modification module
Now let us discuss all steps of generation the modified allophone. The prosody modification module receives the initial allophone with pitch marks from database and creates the initial sequence of acoustic segments (step P1). Each segment has it own number and duration witch is defined in speech database that was calculated during the database creation. Next step (P2) is analyzing the requirements, which is specified in control information file and generating the result sequence of segments. Each element in this sequence has reference to initial element and the new duration of segment is calculated. To avoid some unnaturalness the algorithm realized in this step makes some changes in case of continuous sequence of elements that has reference to the same initial segment.
In the process of formation of the melodic contour each elements of the result sequence is given duration that is calculated by linear way between the values in the ‘start’ and ‘end’ points of the tonal movement. It brings some shade of the unnaturalness because it does not reflect natural fluctuation of fundamental frequency – that is perceived by the listener as ‘computer voice’. This could be observed during the essential increase of the duration of the allophone as for example the synthesis of the ‘singing voice’ – in which the fundamental frequency becomes fixed in the concrete value. In real speech signal fundamental frequency changed occasionally in certain limits around the given value.
Works of Klatt (Klatt and Klatt 1990) suggest the simple formula which describes the occasional fluctuation of fundamental frequency in speech:
This additional fluctuation of fundamental frequency enhances naturalness of the synthesized speech. In our TTS system this formula was converted to more complex variant with two parameters:
where A = characterizes the degree of fluctuation of the period of the fundamental frequency and its diapason of values is between 0 and 100. K – the degree of casualty or quasi-periodicity. The fluctuation value (∆T) is calculated for each element and is added to the value of pitch period (T) of this element. This is realizing in step P3. Transition to this variant of formula is motivated first and foremost by the model which we use for prosody modification. The usage of parameters gives the possibility to enhance or to reduce the influence of this formula on the synthesized speech. When A=0 fluctuation is absent. According to the tests, the most ‘natural’ phonation is achieved when:
A=4 K=0.00005 ( 3 )
These values are used as default values in our system. In the course of further increase of parameter A for example when A=40, the effect of “sob” is observed – that could be explained by significant vibration of fundamental frequency.
The next step is generating new modified allophone using the result information, which has been calculated in the previous steps. The modified allophone is formed from sequence of result segments by using OLA (overlap and add) technology. In systems based on TD-PSOLA technology the type and size of window function has the special significance. They are chosen to achieve the most exact spectral accordance between synthesized and real speech. Also great significance has timeline location of the window function against period. From this time we can talk about the problem of choosing ‘start point’ of the period. There exists several variants of choice of these parameters and due to their small noticeable difference in perception we have implemented several of these choices. They differ by window function and the localization of window within period. We have done several tests and found that it is difficult to choose the best from them and in our system we decided to leave some of them and user can switch between them.
The last step is energy modification of the result allophone. After implementing any PSOLA algorithms the energy of the result acoustic signal is changed and we need to normalize it to some value. The normalization algorithm is done in this step. In our system we can choose the way of normalization. The result allophone can be normalized to the average energy or his energy can be increased or reduced to some value. In real speech signal the average energy of each period realizes not only the given energetic contour but is modified according to the casual law around the local average energetic value. We may assume that in order to improve the quality of synthesized speech it is needed to take into consideration this particular low or to talk about its mathematical realization. We haven’t yet investigated into this sphere but it is known that additional modification will cause certain tangible effect on the synthesized speech. For example if we take some kind of sinus periodical formula thus in some value of the period for this formula we receive the acoustic effect which is called the ‘amplitude vibrato’. In the current version of synthesizer we have already reserved the place for this inquiry.
References- Babkin, A. V., Zakharov L.M. (1999): Testing of “Text-to-Speech” System Developed in MSU. [in:] International Workshop “Speech and Computer” SPECOM99., Moscow.
- Babkin, A. V. (1998): Automatic synthesis of speech — problems and methods of speech signal generation. [in:] Proceedings of International Workshop “Dialogue98” (Computational Linguistics and its Applications), Kazan', pp. 425-437.
- Krivnova, O.F. (1998): TTS synthesis for Russian language (second version for female voice). [in:] Proceedings of International Workshop “Dialogue98” (Computational Linguistics and its Applications), Kazan'.
Internet locations:
- http://isabase.philol.msu.ru/SpeechGroup/