|
| Паузирование при автоматическом синтезе речи |  |
| |
| Автор | Сообщение | Паузирование при автоматическом синтезе речи |
|---|
mia
V.I.P.
Сообщений : 184
Репутация : 7
 |  mia mia | :: Сб Фев 21 2009, 11:54 |
Сб Фев 21 2009, 11:54 | |
| Паузирование при автоматическом синтезе речи
О.Ф.Кривнова, И.С.Чардин
При автоматическом синтезе речи по произвольному тексту одной из важных задач является локализация границ интонационных фраз и выбор фонетических средств их реализации. Под интонационной фразой мы понимаем связный, грамматически организованный фрагмент текста (предложение или его часть), которому при синтезе речи приписывается одна интонационная модель [Кривнова 1998]. Паузированием мы называем закономерности, связанные с реализацией физических пауз на интонационных границах.
Необходимость правильного интонационного членения текста, в том числе его паузирования, в автоматическом синтезе речи обусловлена по крайней мере двумя причинами. С одной стороны, вместе с другими просодическими средствами паузы принимают участие в передаче определенных синтаксических и смысловых отношений, часто выступая как средство смыслоразличения. Достаточно вспомнить широко известный пример: "Казнить нельзя / помиловать" или "Казнить / нельзя помиловать". С другой стороны, при восприятии звучащего текста слушающему необходимо текущим образом производить лингвистическую обработку текста, запоминать ее результаты и строить смысловую структуру. Временные интервалы, которые создаются паузами, облегчают для него процесс такой обработки, и это надо учитывать при озвучивании текста синтезатором.
Как показали результаты проведенных нами экспериментов, проблема паузирования тесно связана с более общей проблемой вариативности манер чтения. Поэтому вопрос о выборе опорной манеры чтения для разработки автоматического синтеза речи также оказывается в фокусе нашего внимания. Кроме того, в работе дается краткий обзор литературных данных, посвященный классификации пауз с точки зрения их типов и функций в спонтанной речи и читаемом тексте.
Паузы при чтении текста: типы, функции и параметры
Традиционно под термином "пауза" понимают такое фонетическое явление, как перерыв в артикуляции и соответствующий ему физический перерыв в речевом сигнале. По соображениям функционального и перцептивного тождества к паузам относят, кроме того, еще и явления резкой смены тона и/или других просодических характеристик в месте интонационной границы, которые воспринимаются как нарушение плавного течения речи.
О паузах, реализуемых отрезком нулевой интенсивности в сигнале, Л. К. Цеплитис [Цеплитис 1974] предлагает говорить как о темпоральных, в противоположность нетемпоральным, в реализации которых такого отрезка нет. При этом к темпоральным паузам относятся также случаи, когда промежуток между двумя сегментами заполнен каким-то звуком (например: "Я позвоню… мм… около восьми"). Такая терминология позволяет подчеркнуть важный признак – наличие или отсутствие у паузы временного измерения в физическом смысле слова, позволяя в то же время различать заполненные и незаполненные темпоральные (физические) паузы.
Четко сформулировать, какие именно контрасты интенсивности, основной частоты и длительности создают обязательный эффект нетемпоральной паузы, пока не удалось. Трудности, возникающие при описании условий возникновения такой паузы, приводят авторов к ее трактовке как категории целостного восприятия: восприятие нетемпоральной паузы зависит не только от акустических показателей, но и от информации более высоких языковых уровней. Так, М.Г. Каспарова [Каспарова 1965] пишет: "Сами по себе интонационные контрасты не всегда обеспечивают восприятие паузы. Кроме того, можно привести примеры, когда восприятие "пауз" на стыке синтагм происходило при весьма плавных интонационных изменениях. <…> Восприятие интонационных контрастов как паузы в речи определяется не только и не столько их физическими характеристиками, сколько смысловым содержанием речевого сигнала. Всякое несоответствие в этом плане компенсируется стереотипом, выработанном у человека системой мышления и системой языка". Иначе говоря, просодический контраст воспринимается как паузальный разрыв только в тех точках текста, которые разрешаются интонационным членением. Ожидание интонационной границы порождает восприятие паузы даже в том случае, когда просодические характеристики на граничных участках соседних интонационных фраз не создают значительного контраста. С точки зрения синтеза речи, как автоматического, так и естественного, понятие нетемпоральной паузы является, на наш взгляд, лишним: существенно лишь понятие интонационной границы и физической паузы как средства ее реализации (не единственного, но наиболее надежного). Для объяснения поведения слушающего при восприятии звучащего текста оно также, по-видимому, не нужно. Слушающему важно определить место интонационной границы на основании различных текстовых ключей, причем не только акустических. Единственной ситуацией, когда широкое понятие "перцептивной" паузы оказывается полезным, являются специальные перцептивные эксперименты, в которых надо получить данные о восприятии испытуемыми разрывов в звучании текста с целью их дальнейшей фукциональной и фонетической интерпретации.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:55 |
Сб Фев 21 2009, 11:55 | |
| Функциональная классификация пауз
В качестве основания для классификации в литературе часто выступают не акустические характеристики пауз, а их функции. У разных авторов наблюдаются значительные расхождения при функциональной классификации пауз. Несмотря на это, одно из вводимых разграничений оказывается достаточно общим. Паузы делятся прежде всего на грамматические, отделяющие друг от друга интонационные фразы, и неграмматические, не имеющие отношения к интонационно-смысловому членению речи. Последние часто делятся на выделительные паузы и паузы хезитации (паузы колебания); вместе с грамматическими паузами они образуют простую трехчленную классификацию, которая отражена в [Светозарова 1982; Ларченко 1990].
Следует заметить, что в звучащем тексте возможны ситуации, когда пауза может быть сигналом, обозначающим интонационную границу, и одновременно выполнять какую-либо другую функцию, например, выделительную. Такая пауза будет синкретичной, совмещающей грамматическую и выделительную функции.
Далее мы будем рассматривать грамматические паузы, поскольку только они носят непроизвольный характер, и их появление в звучащем тексте может быть с некоторой надежностью предсказано. В этом смысле очень удачен термин "автоматическая синтаксическая пауза", применяемый в работах Ф. Гольдман-Эйслер [Гольдман-Эйслер 1961]: он подчеркивает тот факт, что использование пауз этого вида достаточно жестко регулируется правилами, и велика вероятность того, что паузальное оформление грамматических пауз у разных чтецов будет одинаково.
Факторы, определяющие грамматическое паузирование
Совокупность факторов, оказывающих влияние на расстановку пауз при чтении, достаточно хорошо известна. Очевидно, что интонационное членение и использование пауз для маркировки его границ мотивировано семантически, синтаксически и фонетически, а также до некоторой степени определяется когнитивными и физиологическими причинами. Однако каков относительный вес этих факторов и то, как они взаимодействуют между собой, остается открытой проблемой.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:55 |
Сб Фев 21 2009, 11:55 | |
| Когнитивный и физиологический факторы
Причиной появления паузы могут быть не только синтаксические или семантические факторы, но и иные воздействия. Так, Ж. А. Дозорец указывает, что объяснение объективной необходимости возникновения пауз в речи следует искать, во-первых, в особенностях запоминающей и аналитико-синтетической способности мозга и, во-вторых, в естественном ритме человеческого дыхания. Как показали эксперименты, проведенные этим автором, пауза обязательна в любой фразе, содержащей более 8 слов. Кроме того, выявлена тенденция к уменьшению количества пауз во фразе, включенной в контекст, по сравнению с изолированным произнесением той же фразы [Дозорец 1971]. Многие авторы говорят о сильных позициях для паузирования в таких терминах, как расстояние между паузами в графических и фонетических словах, и длительность предыдущего и последующего отрезков относительно данной линейной точки в тексте.
При чтении текста дыхательный ритм является самым существенным физиологическим фактором, который потенциально может оказывать влияние на паузацию. Известно, что средняя частота дыхательных пауз в речи составляет 16-20 в минуту [Потапова, Блохина 1986]. Считается, что это ограничение непосредственного влияния на паузацию не оказывает. Действительно, число ситуаций, в которых синтаксис и семантика диктуют расстановку интонационных границ и, следовательно, возможность появления пауз, достаточно для того, чтобы читающий без особого труда мог подстраивать к ним ритм дыхания, а принцип экономии произносительных усилий предписывает говорящему использовать эту возможность. Л.Р. Зиндер пишет в связи с этим: "Человек, у которого органы речи находятся в нормальном состоянии <…>, делает вдох во время пауз между теми или иными синтаксическими единицами, определяющимися смыслом речи. Механизм дыхания предоставляет для этого широкие возможности благодаря постоянному наличию в легких достаточного запаса воздуха, позволяющего при необходимости значительно продлить время фонации" [Зиндер 1979]. В то же время паузы, которые сопровождаются вдохами, не произвольны по отношению к семантико-синтаксической структуре текста. Обычно они возникают на границе между высказываниями в паузах значительной длительности. Для таких пауз возникает вопрос о причинно-следственных отношениях между паузацией и дыханием. С одной стороны, можно считать, что длинная пауза при чтении возникает независимо от дыхания как средство реализации границы между высказываниями и используется для вдоха, как это обычно и предполагается. В этом случае дыхательный ритм полностью подчиняется интонационно-смысловому членению речи. С другой стороны, можно полагать, что изначально существуют ограничения на возможные текстовые точки завершения дыхательного цикла и длительная пауза, совмещенная с вдохом, является следствием подобных ограничений. При такой трактовке текстовый фрагмент, объединяемый в один дыхательный цикл, может рассматриваться как своего рода мыслительно-дыхательное единство, в создании которого ограничения дыхательного ритма играют не пассивную, а активную роль. В этом случае стратегия текстообразования должна изначально формироваться с учетом потребностей дыхания. Интуитивно это ощущается в различии между текстами с точки зрения их удобства для чтения: есть тексты, которые построены так, что вслух их читать легко, и в то же время некоторые тексты создают впечатление, что они написаны только для визуального чтения. Известно также, что многие писатели в процессе создания текстов "пробуют" их на устное воспроизведение и на слуховое восприятие. Одновременно это означает, что в хорошую манеру чтения текста должна быть встроена осмысленная регулировка дыхания.
Реализация текстово-дыхательных корреляций, как и других аспектов интонационного членения, зависит также от глобальных фонетических установок говорящего (или читающего): от ориентации на полный/беглый тип произнесения, общую громкость и темп речи.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:55 |
Сб Фев 21 2009, 11:55 | |
| Синтаксический и семантический факторы
Интуиция подсказывает нам, что синтаксис играет очень важную роль при паузировании. Подавляющее большинство границ предложений при чтении текста отмечается паузами. Границы интонационного членения (и места появления пауз) внутри предложения часто совпадают с границами частей сложного предложения и синтаксических актантных групп внутри простого. И наоборот, паузы очень редко встречаются внутри таких групп (и это заведомо не грамматические паузы).
В рекомендациях по выразительному чтению предлагаются следующие синтаксические правила для расстановки пауз в местах, где знаки препинания отсутствуют [Розенталь 1994]: пауза ставится между группой подлежащего и группой сказуемого; после обстоятельственных слов, обычно со значением места, времени, причины, а также после дополнений, стоящих в начале предложения; перед союзом и, если при трех и более однородных членах он объединяет два последних.
Однако говорящий выбирает ту или иную синтаксическую конструкцию с тем, чтобы выразить определенный смысл. Иногда синтаксической информации оказывается недостаточно для правильного паузирования. Большинство предложений действительно поддается чисто синтаксическому прочтению по поверхностной синтаксической структуре, которая в русском письменном тексте достаточно полно, хотя и не всегда отражается знаками препинания (ср. известный пример синтаксической омонимии такого рода "как удивили его слова / брата" и "как удивили его / слова брата"). Но бывают и исключения. Как правило, они связаны актуальным членением, которое важно для создания смысловой связности текста. Рассмотрим пример, который приводит П. Адамец [Адамец 1966] (также обсуждается в [Николаева 1979]): "место для лагеря выбрал / Петр Петрович"; "место для лагеря / выбрал Петр Петрович".
В данных предложениях реализовано разное членение на тему и рему; разным вариантам актуального членения соответствует разное интонационное членение и паузация. Чтобы при чтении этих предложений правильно поставить границу и паузу, то есть точно передать коммуникативную установку автора, требуется дополнительная семантическая информация, выходящая за пределы отдельного предложения.
Просодия, и в частности паузы, подчас делают однозначным в речи то, что на письме многозначно; или, если сформулировать то же самое, но по-другому: при анализе звучащей речи гораздо реже оказывается, что одному и тому же фрагменту текста соответствует несколько разных синтаксических и смысловых интерпретаций.
В то же время следует отметить, что для русского языка по сравнению, скажем, с английским, количество случаев, где паузирование при чтении неоднозначно, резко сужается из-за существования развитой и регулярно используемой пунктуационной системы.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:56 |
Сб Фев 21 2009, 11:56 | |
| Параметры пауз
Паузы характеризуются такими параметрами, как место возникновения, длительность и заполнение. Локализация и длительность пауз, несущие четко выраженную функциональную нагрузку, рассматриваются многими авторами. А.Н. Гвоздев [Гвоздев 1949] говорит о паузе как фонологическом средстве языка: "Роль пауз не раз отмечалась наряду с другими средствами для разграничения разных значимых сочетаний. Особенно ясна она в разграничении речевых тактов", – очевидно, здесь и в подобных контекстах речь идет о локализации пауз. Далее А.Н. Гвоздев пишет: "По-видимому, в качестве различительного средства фигурирует и длительность пауз; именно разная продолжительность их помогает группировать речевые элементы, устанавливая между ними перспективу по большей или меньшей их близости и намечая единства высшего и низшего порядка. Кажется, нет основания искать устойчиво выраженных, постоянно сохраняющихся степеней длительности пауз; наоборот, они относительны и только соотносятся одна с другой внутри определенного речевого целого". Вот один из случаев, разбираемых А.Н. Гвоздевым в этой связи: "Учился он жадно, | довольно успешно || и очень хорошо удивлялся" (Горький, Мои университеты). Здесь, если пауза после "жадно" по длительности такая же или больше, чем пауза после "успешно", словосочетание "и очень хорошо" интонационно входит в перечисление обстоятельств, что приводит к появлению невозможной смысловой связи между обстоятельством "довольно успешно" и глаголом "удивлялся". Поэтому после "успешно" требуется пауза большей длительности, чем после "жадно". Таким образом, длительность пауз оказывается параметром, отражающим семантико-синтаксическую иерархию частей произносимого текста; при этом соотношение длительности пауз несет большую нагрузку, чем изменение абсолютных значений.
Перцептивная категоризация пауз по длительности исследовалась многими фонетистами. В результате экспериментов, проведенных М. Г. Каспаровой, было установлено, что интервал длительностью от 3 до 25 мс воспринимается аудиторами как треск, щелчок, помеха на магнитофонной ленте и т.д. Интервал от 25 до 100 мс оценивается как нарушение в звучании, но как пауза в большинстве случаев не осознается, хотя "в позиции, обусловленной для членения нормой языка" паузы могут восприниматься даже начиная с 20-25 мс [Каспарова 1971]. Достаточно надежное восприятие паузы в речевом сигнале происходит при достижении длительности 150-200 мс (значение, близкое к значению средней длительности слога). Впрочем, длительность пауз варьируется в широких пределах и зависит помимо семантико-синтаксических факторов от просодического контекста, стилистических характеристик текста, а также от вида речевой деятельности. По данным других авторов, нижний порог восприятия паузы составляет порядка 200 мс [Бомер и Диттман 1962].
Эксперименты показывают, что в области значений длительности пауз от 200 до 300 мс находится поведенчески значимая категориальная граница, разделяющая поверхностно-артикуляторные паузы, отражающие ритмические швы (слева от границы), с одной стороны, и паузы, являющиеся "рефлексом глубинных пауз-остановок в работе фонетического процессора", типичных для собственно интонационных швов, с другой [Кривнова 1995]. Паузы первого типа приводят к "минимальному прерыванию плавного развертывания речи"; появление в звуковой оболочке высказывания пауз второго типа "приводит к появлению значительной и отчетливо воспринимаемой на слух разрывности в звучащем тексте".
Обнаружено также, что чем более дробной является предлагаемая в эксперименте градация пауз по длительности, тем менее однородны и надежны результаты аудирования. На основании проводившегося в ЛЭФ МГПИИЯ им. М. Тореза эксперимента, в ходе которого аудиторы оценивали длительность пауз в читаемых русских текстах по трехбалльной шкале (1 – короткая пауза, 2 – средняя пауза, 3 – длинная пауза; затем при усреднении данных были введены промежуточные ранги 1',2',3'), были сделаны следующие выводы:
Паузы длительностью от 60 до 600 мс, отмеченные как 1,1' и 2, маркируют межсинтагменные границы.
Паузы группы 3', длительность которых колеблется от 600 до 1800 мс, находятся на межфразовых границах.
Паузы с оценками 2' и 3 встречаются на границах обоих типов. При этом длительность пауз не превышает 800 мс [Потапова, Блохина 1986].
Т. М. Николаева, исследуя интонацию сложного предложения в славянских языках, также находит в полученных ею данных основания для разделения внутрифразовых пауз на минимальные (включая нулевую паузу), средние и большие. Это разделение подтверждается соотношением данных типов пауз с другими компонентами интонации, в результате чего становится возможным выделение ограниченного числа неслучайных комбинаций интонационных признаков (по терминологии Т. М. Николаевой, интонем), передающих смысловую информацию [Николаева 1969].
Одной из основных причин вариативности в перцептивной категоризации длительности пауз является темповые характеристики речи. Б. Б. Здорововой было установлено, что межфразовые паузы при среднем темпе произнесения по оценке аудиторов в 65% случаев оцениваются как длительные, в остальных случаях – как средние. При быстром темпе произнесения паузы на фразовых границах оценены аудиторами как средние в 75% случаев, остальные паузы отнесены к разряду кратких. При медленном темпе межфразовые паузы были оценены как длительные в 96% случаев, и только 4% приходится на долю средних пауз. На границах между синтагмами преобладание средних пауз фиксируется аудиторами для среднего (53%) и медленного (58%) темпа. В быстром темпе большинство межсинтагменных границ характеризуется нетемпоральными паузальными разрывами (54%).
Уменьшение вариативности в перцептивной оценке длительности пауз достигается переводом их абсолютной длительности в относительную. Относительная длительность измеряется обычно количеством сегментных единиц, которые при данном темпе произнесения имеют ту же абсолютную длительность. На материале английского языка было показано, что при чтении длительность краткой паузы равна длительности фонетического слова (акцентной единицы). Паузы такой длины разделяют в английском языке минимальные интонационные фразы (синтагмы).
Наряду с анализом длительности пауз представляет интерес анализ такого акустико-физиологического параметра, как их заполнение. Мы уже отмечали, что при чтении текста время длинной паузы часто используется говорящим для дыхания: чтобы сделать вдох, выдох или даже осуществить несколько дыхательных циклов. Средние паузы обычно сопряжены с выдохом. Короткие паузы, как правило, реализуются с помощью гортанной смычки, заполняются продолжающейся вокализацией или же характеризуются отсутствием какого-либо артикуляторного заполнения.
До начала широкого применения компьютеров в речевых исследованиях дыхательное заполнение пауз исследовалось с помощью специального устройства – плетизмографа, которое фиксировало состояние легких диктора в речи. Компьютерные программы сделали общедоступными средства визуализации речевого сигнала. Они также позволяют осуществить многократное увеличение его амплитуды. При этом исследователь может непосредственно оценить на слух, через какую полость осуществляется дыхание в случае каждого конкретного вдоха/выдоха. Современный компьютерный инструментарий, кроме того, делает возможным анализ взаимосвязи между паузами, их заполнением, другими особенностями реализации и соседними сегментами речи.
В целом следует признать, что результаты исследований корреляции между параметрами пауз и факторами, определяющими паузирование, нельзя считать полными и удовлетворительными. Использование современных компьютерных технологий открывает новые возможности для выявления природы данной корреляции.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:56 |
Сб Фев 21 2009, 11:56 | |
| Интонационное членение и паузирование при автоматическом синтезе речи
Локализация интонационных границ в озвучиваемом тексте составляет одну из главных задач акцентно-интонационного транскриптора, который является обязательным блоком в любой системе автоматического синтеза речи. В этом же блоке для каждой интонационной границы решается вопрос об оформлении границы физической паузой, и в случаях, где это признается необходимым, паузе приписывается ее категориальная длительность [Кривнова 1998].
На сегодняшний день актуальна прежде всего задача порождения для каждого предложения в текст нейтрального варианта интонационного членения и сопутствующей этому варианту физической паузации. Для этого надо уметь находить в тексте те ситуации, в которых на интонационной границе, по определению коррелирующей с синтаксисом, появляется физическая пауза и уметь оперировать ее длительностью. В конечном итоге нужно научить систему синтеза расставлять в письменном тексте те интонационные границы, которые сопровождаются всегда или в подавляющем большинстве случаев (в чтении разных людей) физическими паузами и уметь задавать их длительность.
Как показал обзор имеющихся в литературе данных, взаимодействие факторов, влияющих на паузирование, плохо изучено. Выявлены скорее тенденции, а не закономерности, и даже для замеченных тенденций нет достаточно формализованного описания текстовых ситуаций, характеристики которых могли бы служить ключами для автоматической расстановки интонационных границ и пауз. Нет также сколько-нибудь достаточных статистических данных, которые позволяли бы отделять нормативное (нейтральное) прочтение текста от допустимого (не нейтрального) или же ошибочного.
Практика создания автоматических систем синтеза речи по произвольному тексту показывает, что важнейшими ключами для определения интонационных границ при озвучивании текста являются знаки препинания. Однако в общем случае для решения этой задачи необходим автоматический синтаксический анализ, который на текущий момент полностью нигде не реализован, в том числе и для русского языка. В то же время разработка конкретных синтезаторов для разных языков свидетельствует о том, что для расстановки интонационных границ и их паузации восстановление полной синтаксической структуры предложения необязательно. Признано, что организация просодических составляющих проще, чем связанные с ними синтаксические зависимости. Другими словами, просодическая структура предложения оказывается не такой глубокой, как синтаксическая: существуют такие аспекты синтаксической структуры, которые нерелевантны или, точнее, мало релевантны для просодии [Монаган 1990].
Если принять во внимание эти соображения, то не покажется удивительным тот факт, что при создании коммерческих систем автоматического синтеза речи внимание уделялось развитию методов эвристического анализа структуры синтезируемого текста, а не методов его полного синтаксического анализа. Рассмотрим подробнее, как решается задача расстановки интонационных границ в тексте в различных работающих системах автоматического синтеза речи (АСР). Представляется целесообразным отдельно говорить о разных типах систем.
Разделим их на следующие классы:
Системы, которые обходятся анализом структуры текста с помощью “вручную” обнаруженных эвристик (экспертные системы).
Системы, в которых проводится полный синтаксический анализ с использованием формальных грамматик.
Системы, где используется вероятностный анализатор текста, основанный на статистической модели, параметры которой получены через обучение по аннотированной тексто-речевой базе данных.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:56 |
Сб Фев 21 2009, 11:56 | |
| Эвристический анализ текстаКогда человек читает предложение вслух, он обычно начинает произносить его до того, как прочтет до конца. Из этого следует, что можно получить всю информацию, необходимую для интонационного членения текста и расстановки грамматических пауз из локального анализа предложения. Эта простая мысль лежит в основе попыток многих разработчиков систем АСР избежать проблем, связанных с вычислительной требовательностью и сложностью разработки полномасштабных синтаксических анализаторов за счет использования поверхностных эвристик. Первоначально такие эвристики основывались исключительно на использовании знаков препинания [О’Шонесси 1990], следуя ошибочным представлениям о пунктуации как о единственном надежном отражении членения и физического паузирования. Понятно, что такое решение для английского языка не принесло большого успеха, да и для любого другого языка оно едва ли является удачным. Во-первых, в английском языке многие интонационно существенные границы оказываются неотмеченными знаками препинания (например, такая важная синтаксическая граница, как в предложении: "I found a book / I wanted to read"). Во-вторых, многие знаки препинания ставятся в местах, где не проходит никаких интонационных границ. Для английского языка известный случай такого использования пунктуационных знаков – последовательность разделенных запятыми определений, выраженных одиночными прилагательными, как в "the old, dark, red house". Более совершенный метод состоит в том, чтобы расставлять границы не только на основе пунктуации, но также между знаменательными и служебными словами, причем последние понимаются как разделители. При внесении небольших изменений и дополнений этот метод показывает очень хорошие результаты для правоветвящихся языков – языков, в которых служебные слова обычно находятся в крайне левой части составляющих (большинство европейских языков, в том числе – русский). Данный метод используется в классических системах АСР Prose-2000, Infovox SA-101 и DECtalk, причём применяющийся в последней словарь, помимо служебных слов, включает еще и глагольные формы. Именно в рамках этого метода работает очень грубый, но эффективный алгоритм (т.н. chunks’n’chinks-алгоритм), предложенный Либерманом и Черчем для расстановки интонационных границ в английском тексте [Либерман и Черч 1992]. Согласно предложенному алгоритму минимальная просодическая группа (f-группа в терминологии авторов) выделяется как последовательность функциональных (function) слов (chinks), за которой следует последовательность знаменательных (content) слов, (chunks). При этом для улучшения результатов работы алгоритма объектные местоимения (him, them etc.) отнесены к chunks, а финитные формы глаголов – к chinks (см. выше – похожее решение относительно глагольных форм в DECTalk TTS). Рассмотрение следующего примера из английского языка показывает, что некоторое улучшение результатов анализа налицо: - Цитата :
- Function words / Content words
I asked
them if they were going home
to Idaho
and they said yes
and anticipated
one more stop
before getting hom
Chinks / Chunks
I asked them
if they were going home
to Idaho
and they said yes
and anticipated one more stop
before getting home Подобным образом производят членение Кене и Кагер [Кене и Кагер 1989] для голландского языка; такого же рода правила использовались первоначально в системах АСР для французского языка [Ларрёр и др. 1989], [Келлер и др. 1993] и для итальянского языка [Балестри и др. 1993]. Когда членение произведено, необходимо ввести иерархию границ, чтобы отдельные просодические группы складывались в более крупные просодические единицы. Данная задача требует синтаксического анализа состава каждой просодической группы в отдельности [Мертенс 1993a, 1993b] и в связи с другими выделенными группами. Она также решалась с помощью эвристик, впрочем, с гораздо меньшим успехом [Кене и Кагер 1989]. В некоторых системах более крупное членение производится по знакам пунктуации. |
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:58 |
Сб Фев 21 2009, 11:58 | |
| Полный синтаксический анализ текста
Создатели коммерческих систем автоматического синтеза речи обычно стараются обойтись при расстановке интонационных границ анализом поверхностной синтаксической структуры.
В системах, развиваемых в научных лабораториях, полный анализ иногда применяется. Эти попытки привели исследователей к следующему выводу: “Практически все методы анализа и их возможные комбинации применялись к проблеме анализа произвольного текста. Однако до сих пор принятие решения относительного того, какие именно методы анализа будут применяться в данной системе АСР, определялось степенью интереса создателей системы к синтаксическому анализу, а не требованиями, предъявляемыми собственно задачей синтеза” [Монаган 1990].
Обычно для полного синтаксического анализа текста используются формализмы, расширяющие контекстно-свободные грамматики. Наиболее часто базовыми являются формализмы, основанные на грамматиках типа ATN (Augmented Transition Network), DCG (Definite-Clause Grammars) и UG (Unification Grammars). ATN используются главным образом для синтаксического анализа внутри актантных групп, DCG и UG – более мощные формализмы.
Если для данного предложения корректно построена соответствующая ему поверхностная синтаксическая структура, возникают дальнейшие проблемы, поскольку приписывание интонационных границ, непосредственно отталкивающееся от синтаксической структуры предложения, обречено на высокий процент ошибок: известно, что интонационное членение связано с синтаксической структурой опосредованным образом. Для решения этих проблем применяются специальные переписывающие правила. Полный алгоритм для немецкого языка может быть найден в [Трабер 1993], английский, широко упоминающийся в литературе – в [Баченко и Фитцпатрик 1990].
Известны случаи, когда системы, применявшие первоначально подход, основанный на DCG (Definite-Clause Grammars) [Линдстрём и др. 1993], затем переходили на использование более простых алгоритмов, построенных на анализе частеречной принадлежности слов и правил [Лунгквист 1994].
Остается отметить следующее: несмотря на некоторое отставание полного синтаксического анализа по технологичности от других методов, его развитие имеет важное теоретическое значение для выяснения характера и значимости связей между синтаксической и просодической структурами текста.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:58 |
Сб Фев 21 2009, 11:58 | |
| Статистический анализ текста
Для того, чтобы понять суть статистического анализа текста в системе автоматического синтеза речи, очень удобна метафора обучения. В обычном обучении могут применяться два различных метода: обучение через объяснение (по правилам), и обучение через пример (по образцу). Оба эти подхода были применены к обучению систем синтеза. Система АСР может либо работать по эксплицитно сформулированным аналитическим правилам, либо использовать вероятностные правила, построенные путем оценки параметров вероятностной модели грамматики на материале аннотированной тексто-речевой базы (корпуса) данных. При этом модель грамматики, используемая в реальных системах, обычно достаточно проста. Так, при построении статистических правил для расстановки интонационных границ, часто используют следующий подход. Каждое предложение рассматривается как марковская цепь, в которой состояниям соответствуют слова, а переходам – вероятности гипотетически возможных границ разных типов (здесь отсутствие границы – это граница с нулевой вероятностью). Поскольку даже очень большая аннотированная речевая база данных не будет содержать достаточно материала для того, чтобы с требуемой степенью надежности оценить вероятность появления границы того или иного типа между любыми двумя словами языка, слова группируются в так называемые классы эквивалентности, чаще всего на основе частеречной принадлежности. При такой группировке состояниям марковской цепи соответствуют части речи, и необходимый материал собрать можно.
Впервые марковская модель, в которой подсчитывалась вероятность появления цепочки из N слов, была использована в распознавании слитной речи [Джелинек и др. 1976]. С тех пор в связи с моделями этого типа принято говорить об N-граммах, в зависимости от количества N слов в цепочке. Как легко видеть, модель, описанная в предыдущем абзаце, приводится к триграммам, если граница (определенного типа) учитывается как состояние цепи наравне со словами. Использование N-грамм, в особенности биграмм и триграмм, получило в последнее время широкую популярность в зарубежной компьютерной лингвистике, поскольку выяснилось, что этот подход удачным образом сочетает в себе простоту и эффективность.
Сам создатель N-граммной грамматики, Ф. Джелинек, пишет: "То, что этот простой подход оказался таким успешным, является постоянным источником раздражения для меня и некоторых моих коллег. У нас есть основания считать, что можно построить лучшие модели языка, мы полагаем, что нам известно множество слабых мест в модели триграмм, и тем не менее, каждый раз, когда мы создаем более или менее сложную модель, оказывается, что она не оправдывает наших ожиданий" [Джелинек, 1991].
В последнее время для предсказания интонационных границ исследовались именно перспективы применения триграмм [Сандерс и Тейлор 1995], хотя этому подходу действительно присущ ряд ограничений. Границы не могут приписываться независимо друг от друга. В самом грубом приближении, получающиеся при их постановке речевые отрезки должны иметь примерно одинаковую длину [Мартин 1987; Баченко и Фитцпатрик 1990]. Кроме того, при приписывании интонационных границ должна учитываться синтаксическая структура и границы предложений, но при учете такого маленького контекста это не всегда возможно. Расширение контекста влечет за собой увеличение тексто-речевого корпуса и количества вычислительных усилий, требуемых для обучения системы. Как вычислительные ресурсы, так и ресурсы для наращивания объемов базы при таком подходе быстро исчерпываются.
Удачным образом, для статистической расстановки интонационных границ был найден другой, более эффективный метод, в котором правила, извлекаемые из базы, организуются в так называемые деревья принятия решений, полученные с помощью классификационно-регрессионных деревьев (англ. CART, Classification and Regression Trees; этот подход подробно описан в [Бриман и др. 1984]). Использование классификационно-регрессионных деревьев позволяет автоматически выбрать самый значимый из контекстных параметров. Алгоритм допускает применение как дискретных, так и континуальных параметров, т.е. параметров, принимающих значения из списка или из определенного диапазона, соответственно. Наконец, результаты применения данного алгоритма исследователь может непосредственно интерпретировать и оценить, так как классификационно-регрессионные деревья превращают аннотированную речевую базу в двоичное дерево принятия решений. В каждом нетерминальном узле содержится вопрос, требующий ответа "да/нет" для оценки значимости контекстного параметра, приписанного к данному узлу; для каждого из возможных ответов существует ветвь, ведущая к следующему вопросу. Вопросы и возможные ответы на них зависят от значений контекстных параметров, которые исследователь выделил как релевантные. В вопросах о дискретных параметрах значения разделены на два непересекающихся множества, соответствующие ответам "да/нет". В вопросах о континуальных параметрах диапазон значений параметров разбивается на две непрерывные части граничной точкой. Терминальные узлы дерева, называемые также листьями, находятся в соответствии с метками аннотированной тексто-речевой базы данных (в нашем случае, интонационными границами, множество которых включает и "отсутствие границы").
Метод классификационно-регрессионных деревьев был успешно применен для решения проблемы выделения инонационных границ в английском тексте [Вэнг и Хиршберг 1991]. Аннотированная речевая база данных состояла из 298 высказываний из корпуса DARPA Air Travel Information System (ATIS), в которых вручную были размечены границы и их типы. Использовавшиеся контекстные параметры включали в себя: длину высказываний в словах и миллисекундах, темп, измеренный в словах в секунду, а также расстояние потенциальной границы от начала и конца предложения (в словах и секундах). Синтаксический фактор учитывался через частеречную принадлежность четырех слов, окружающих потенциальную границу, и через анализ составляющих. Процент успешной расстановки границ составил около 90% , что является очень хорошим показателем. Результаты [Вэнг и Хиршберг 1991] используются в текущей версии системы автоматического синтеза речи корпорации AT&T [Спроат и др. 1992]; в дальнейшем они могут быть улучшены за счет обучения системы на аннотированном корпусе большего объема.
Статистические методы при расстановке интонационных границ оцениваются как очень перспективные. По мере того, как будут создаваться аннотированные речевые базы данных для разных языков, эти методы будут применяться все шире и шире.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:58 |
Сб Фев 21 2009, 11:58 | |
| Решения для русского языка
На материале русского языка грубый анализ поверхностной структуры, подобный описанным выше подходам, используется в системе автоматического синтеза речи, разработанной в Петербурге [Жарков и др. 1995].
Этот анализ также базируется на знаках препинания, но использует дополнительно информацию о частеречной принадлежности слова и анализ некоторых синтаксических связей. Оригинальный момент в алгоритме, предложенном в [Жарков и др. 1995] состоит в том, что в процессе анализа произвольного текста указываются не только возможные точки возникновения границ интонационных групп, но и точки, где такие границы не могут возникнуть ни при каких обстоятельствах.
Еще более простой алгоритм применяется на сегодняшний день в системе автоматического синтеза речи, разрабатываемой в МГУ им. М. В. Ломоносова. Физическое паузирование привязано к приписыванию интонационных моделей, которое по умолчанию связано со знаками препинания. При работе системы в режиме ручной разметки пользователь может самостоятельно указать, в каких местах текста находятся интонационные границы.
Разработчики систем автоматического синтеза ощущают большую потребность в проведении специальных исследований интонационно-смыслового членения и паузирования в русском языке, ориентированных на задачи автоматического синтеза. Представляется интересным опробовать наиболее успешные из эвристических подходов, применяемых в системах синтеза для иностранных языков, прежде всего chinks'n'chunks, на материале русского языка, оценить доступность технологической базы, необходимой для создания аннотированных речевых корпусов и использования статистических методов.
Проблема нормативности интонационно-смыслового членения текста и его паузирования
В области супрасегментной фонетики на сегодняшний день не существует общепринятой методики оценки текстов как нормативных или ненормативных с точки зрения интонационного прочтения и паузации. Между тем этот вопрос очень важен как для автоматического синтеза речи на основе любых методов предварительного анализа письменного текста, так и для обучения осмысленному выразительному чтению. Нами был проведен специальный эксперимент, направленный на поиск определяющих особенностей такой нормы. Эксперимент преследовал две цели: 1) определить степень однородности интонационного членения и паузации при чтении одного и того же текста разными людьми; 2) получить оценки нормативности (приемлемости) разных прочтений, которые могли бы служить основой для определения опорной манеры чтения для воспроизведения ее особенностей при синтезе речи.
Для решения указанных задач использовалась специальная методика оценки нормативности прочтений, разработка которой является нетривиальной задачей. Основу такой оценки составило анкетирование испытуемых. Несколько испытуемых, привлеченных для оценки прочтений, должны были ответить на вопросы специально составленной анкеты. Анкета составлялась таким образом, чтобы отобрать нейтральные прочтения, поскольку правильное паузирование входит в комплекс правильного просодического оформления речи, характеризующего нейтральную манеру чтения. Кроме того, анкета содержала вопросы, посвященные специально оценке правильности паузирования. Ответам на эти вопросы при анализе результатов эксперимента был придан большой вес, так как его результаты должны использоваться при построении алгоритма паузирования. После отбора наилучших прочтений было проведено сравнение локализации пауз. Основной задачей сравнительного анализа была проверка гипотезы о единообразии паузального членения разными чтецами при нейтральной манере чтения.
Эксперимент, схожий с нашим, упоминается в [Светозарова 1982]. Он не был специально ориентирован на паузирование, в нем решались более общие задачи. Так, одна из его задач состояла "в выделении имеющих надындивидуальную природу типов чтения". В этом эксперименте рассматривалось 150 прочтений одного текста разными дикторами. При этом было выявлено, что "наибольшие различия в прочтении были связаны с синтагматическим членением: количеством синтагм и местом синтагморазделов". Вариативность в членении, по мнению авторов эксперимента, была обусловлена отклонениями от нормы типов чтения многих дикторов. "Место синтагматического членения связано прежде всего с нормативностью членения. <…> Неверная расстановка синтагматических границ – один из явных признаков неграмотного членения" [Светозарова 1982].
По сути, здесь в неявном виде сформулирована гипотеза единообразия паузирования при нормативной манере чтения. В нашем эксперименте мы хотели подтвердить или опровергнуть ее.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:59 |
Сб Фев 21 2009, 11:59 | |
| Материал и методика эксперимента
Материал для эксперимента был любезно предоставлен московской компаний Stel Computer Systems, ведущей разработку системы автоматического распознавания речи для русского языка. Он представляет собой запись 30 прочтений одного и того же специально составленного текста из 358 слов разными дикторами (22kHz, 16 bit, Mono; суммарный объем речевой базы около 400 мегабайт).
Каждое прочтение снабжено фонетической транскрипцией, в которой отмечены локализация и заполнение пауз. Транскрипция была получена путем ручной коррекции и дополнения транскрипции, созданной блоком транскрипции системы автоматического синтеза речи МГУ.
Дикторы различались по полу, возрасту, образованию, а также навыкам чтения вслух. Все они являются носителями русского языка, хотя не у всех произношение вполне соответствовало произносительной норме литературного языка.
Для отбора прочтений с нейтральной манерой чтения было приглашено 6 аудиторов, 4 мужчины и 2 женщины. Им было предложено прослушать все прочтения и про каждое из них ответить на пять вопросов анкеты. В первом из них аудитор должен был дать данному прочтению интегральную оценку по пятибалльной системе. В ответе на второй вопрос требовалось указать, присутствовали ли в прочтении, по мнению аудитора, ненужные или ошибочные паузы. Третий вопрос касался наличия/отсутствия сегментных ошибок. Отвечая на четвертый вопрос, аудитор должен был определить, в каком темпе был прочитан текст (медленно, нормально или быстро). В пятом вопросе ему предлагалось оценить количество пауз в тексте (мало, нормально, много).
Ответы на эти вопросы, с одной стороны, позволяют понять, насколько в целом данное прочтение отклоняется от нейтрального. С другой стороны, они отражают соответствие норме собственно паузирования.
Затем результаты анкетирования были введены в компьютер и переведены в числовой вид. Ответ на первый вопрос – оценка – и сам по себе представлял число. Ответы "да" на второй и третий вопрос (наличие отклонений) получили значение 1, ответы "нет" – значение 0. В четвертом и пятом вопросах значение 1 также получили отклонения от нормы (быстрый/медленный темп, мало/много пауз), а прочтения, оцененные как нормальные, – значение 0. После этого по каждому из вопросов было посчитано среднее по ответам разных аудиторов для каждого прочтения. Чем больше значение среднего в ответах на вопросы со второго по пятый – тем в меньшей степени нормативным является прочтение. Обратная ситуация с оценкой: чем выше средняя оценка, тем лучше прочтение. Поэтому для однородности таблицы оценка была инвертирована: из 5 было вычтено среднее значение оценки.
На базе получившейся таблицы путем взвешивания значений была построена таблица штрафов, а затем путем сложения значений штрафов по всем вопросам были получены суммарные штрафы для каждого прочтения. Таблица штрафов строилась следующим образом. Для каждого вопроса по всем прочтениям были подсчитаны средние значения. Если среднее значение для конкретного прочтения было меньше среднего по вопросу, то его значение умножалось на 2 – так отсеивались маркированные прочтения. Дополнительно увеличивались в два раза значения для вопросов, касающихся пауз, чтобы отклонения в паузировании дополнительно увеличивали общий штраф. Наконец, прочтения были отсортированы по возрастанию значения суммарного штрафа. Прочтения, попавшие в верхнюю часть таблицы, были отобраны как наиболее нейтральные. Для них с использованием результатов имеющейся фонетической транскрипции была построена таблица вероятности постановки пауз в тексте.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:59 |
Сб Фев 21 2009, 11:59 | |
| Выбор нейтральных прочтений
При рассмотрении результатов анкетирования выяснилось, что пять из шести испытуемых использовали вместо предложенной пятибалльной схемы оценки трехбалльную (от 3 до 5), а один – двухбалльную (3/4). Только один раз один из аудиторов поставил двойку одному из дикторов. Средняя оценка составила 3,84.
Среднее значение для ответа на вопрос, присутствовали ли в прочтении ненужные или ошибочные паузы, составило 0,40, для третьего вопроса (наличия/отсутствия сегментных ошибок) – 0,48. Для вопроса про темп среднее также составило 0,48, а для вопроса про количество пауз – 0,36, при этом как темповые отклонения, так и отклонения, связанные с количеством пауз, распределились примерно поровну – одинаково в сторону увеличения и в сторону уменьшения.
После построения таблицы штрафов оказалось, что значения суммарных штрафов распределились равномерно от 0,95 до 12,52. Точек, вокруг которых группировались бы значения, не оказалось.
Тот факт, что для интегральной оценки большинство аудиторов использовало трехбалльную систему, дает основания для разделения этой группы на три части – хорошие, средние и плохие прочтения. Максимальное значение суммарного штрафа составило 12,52; поэтому к хорошим были отнесены прочтения со штрафами от 0 до 1/3*12,52=4,17, к средним – от 4,17 до 2/3*12,52=8,35, и к плохим – от 8,35 до 12,52. В количественном отношении прочтения разделились по группам так: в группу хороших прочтений попало 8 прочтений, в группу средних – 12, и в группу плохих – 9.
Файлы с транскрипциями, предоставленные компанией Stel, содержат составленные профессиональными фонетистами характеристики произносительных особенностей дикторов. Характеристики большинства дикторов из группы хороших прочтений содержат такие квалификации: "достаточно отчетливое произношение, нормативное"; "нормальное произношение"; "хорошее произношение"; "хорошее, отчетливое произношение". В то же время часто встречаются замечания следующего вида: "много звуковых потерь и упрощений в произношении"; "много произносительных упрощений, характерных для беглой речи". Можно и непосредственно на слух оценить различия в типе произнесения – одни дикторы в большей степени тяготеют к полному типу, чем другие. Произношению некоторых дикторов, кроме того, присущи специфические особенности, такие, как особое произношение шипящих и свистящих согласных; слабые взрывы у взрывных согласных в конце фраз; предотвращение слияния слов, начинающихся с гласных, с предшествующей частью фразы за счет сжатия гортани. Это, однако, не помешало им попасть в группу хороших дикторов.
Интересно, как по различным группам разделились дикторы-мужчины и дикторы-женщины. Из 30 прочтений 21 принадлежали дикторам-мужчинам, и только 9 – женщинам. При этом в лучшей группе из 8 прочтений дикторов-мужчин и дикторов-женщин оказалось поровну, в средней группе – треть дикторов-женщин, а в группе плохих прочтений – только 1 диктор-женщина из 9 дикторов. Отсюда можно сделать вывод, что женщины обычно читают лучше мужчин. Правда, среди аудиторов преобладали мужчины, поэтому с полной достоверностью этого утверждать нельзя.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 11:59 |
Сб Фев 21 2009, 11:59 | |
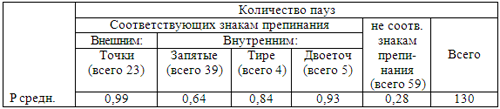
| Паузирование в отобранных прочтенияхДля прочтений, попавших в группу хороших, была составлена таблица вероятности появления пауз в прочитанном тексте, причем нас интересовал прежде всего вопрос о надежности знаков препинания для расстановки физических пауз в тексте при его озвучивании автоматической системой синтеза речи. В отобранных прочтениях дикторы сделали от 63 до 92 пауз, что в среднем составило 73 паузы. Всего разных мест, в которых появлялись паузы при различных прочтениях – 130. Из них 6 – границы абзацев (все дикторы поставили паузы в этих местах); 17 – границы предложений внутри абзацев (средняя вероятность появления паузы для этого типа границ составила 0,99). Средняя вероятность появления паузы для внутренних знаков препинания составила 0,7. В тексте встретилось 48 внутренних знаков препинания, при этом нулевой вероятность появления паузы оказалась в двух случаях (4 % от внутренних знаков препинания). В обоих случаях нулевую вероятность получили запятые перед вводными словами. Меньше 0,5 и больше нуля вероятность появления паузы при внутренних знаках препинания была в 9 случаях. Это составило 19 % от внутренних знаков препинания; в большей части этих случаев знаком препинания также являлись запятые при вводных словах. В то же время данные эксперимента не дают оснований считать, что запятым при вводных словах никогда не соответствует пауза. Широкая семантика и разнообразные функции вводных слов делают задачу принятия решения о постановке при них пауз очень сложной. Кроме того, наши наблюдения показывают, что для этого класса случаев оказывается очень существенным фонетический фактор (длина в фонетических словах). Прояснить картину паузирования при вводных словах могут дальнейшие исследования, специально посвященные этой проблеме. В остальных случаях, когда вероятность появления паузы при запятой составила меньше 0,5, действуют различные факторы. Главными из них являются смысловые отношения между фрагментами предложения и длина (степень распространенности) этих фрагментов. Сбалансированное взаимодействие между указанными факторами существенно и для пауз, появившихся вне знаков препинания (их количество в наших текстах – 59). В целом такие паузы имеют достаточно маленькую среднюю вероятность появления (0,28). При этом вероятность больше или равную 0,5 имеют только 9 из них (16%). В значительной части этих случаев, пауза предшествовала союзу "и", соединяющему распространенные однородные члены предложения, состоящие из нескольких фонетических слов. В одном из случаев та же самая ситуация возникла с союзом "или". Таким образом, однородные члены при распространении имеют тенденцию к интонационному обособлению. Следует обратить особое внимание на то, что большая часть различий в паузальном членении разными дикторами приходится на отрезки текста, обрамленные знаками препинания. При этом внутри проанализированной группы прочтений эти различия не носили системного характера: складывается впечатление, что паузирование вне знаков препинания носит факультативный характер. В то же время, представляются существенными два факта. С одной стороны, паузы вне знаков препинания крайне редко появляются в местах, где их появление нарушило бы синтаксическую структуру текста. С другой стороны, хотя они и появляются в разных местах у разных дикторов, они все-таки появляются, и это обусловлено, по-видимому, когнитивными и/или дыхательными причинами, поскольку чаще всего подобные паузы возникают в отрезках текста большой длины. Не случайно у всех дикторов большинство таких пауз, сопряжено с вдохом или выдохом. Проведенный эксперимент показывает, что даже в группе хороших прочтений наблюдается значительная вариативность интонационного членения и паузации при чтении одного и того же текста. В этом проявляются принципиальные различия в характере интонационной и сегментной нормы: в области интонационно-смыслового членения и, в особенности, физической паузации нормы сильно размыты, они подчиняются запретам (указанием ситуаций, где членение запрещено) и гибким рекомендациям (указанием ситуаций, где членение и паузация возможны), которые действуют на фоне нескольких факторов разной природы (смыслового, риторического, фонетического и физиологического). Поэтому автоматизация синтаксических пауз в реальном поведении говорящего носит весьма относительный характер: жестких правил здесь не так уж много. В нижеследующей таблице приведены статистические данные о корреляции между знаками препинания и паузами в прочтениях, признанных хорошими. |
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 12:00 |
Сб Фев 21 2009, 12:00 | |
| Трудности в создании алгоритма паузирования
Анализируя результаты проведенных экспериментов, мы снова и снова убеждались в том, что прогноз интонационно-смыслового членения и паузирования при чтении конкретного текста представляют собой сложную задачу, решение которой связано с определением баланса между конкурирующими факторами разных уровней.
Тем не менее при чтении текста значительная часть пауз появляется на границах предложений и в местах синтаксических границ, которым обязательно соответствуют внутренние знаки препинания. В нашем экспериментальном тексте с достаточно стандартным синтаксисом количество таких пауз составило около 85 процентов. Таким образом, алгоритм приписывания пауз в системе автоматического синтеза речи должен ставить паузу на внешних знаках препинания, а также в большинстве мест, где встречаются внутренние знаки.
Внутренним знакам препинания не обязательно соответствует пауза. Особенно часто это бывает с запятой, что не удивительно: ведь запятая – самый полисемантичный из пунктуационных знаков. Среди случаев, в которых она употребляется, есть немало таких, в которых паузация не нужна. Для нашего текста это 19% всех случаев употребления внутренних знаков препинания. Но главная сложность приписывания пауз связана с тем, что по мере распространения синтаксических групп и усложнения синтаксической структуры текста доля пауз, соответствующих знакам препинания, существенно уменьшается за счет увеличения пауз вне знаков препинания. Для локализации пауз последнего типа характерна значительная вариативность. В экспериментальном тексте только около 16% пауз, сделанных вне знаков препинания, совпало у разных дикторов.
Подходы, подобные описанному в предыдущей главе chunks'n'chinks или алгоритм, примененный при создании петербургской системы автоматического синтеза речи, позволяют найти большинство потенциальных мест появления интонационных границ, в том числе, вне знаков препинания. Однако совсем не все интонационные границы манифестируются физической паузой. Каждый диктор, читавший наш экспериментальный текст, отмечал такой паузой меньше 20% границ вне знаков препинания, и эти границы в подавляющем большинстве случаев получали разную локализацию у разных дикторов. Если интонационное членение не имело смыслоразличительной функции, выбор конкретной точки из набора возможных оказывался случайным. Допустимость вариаций в достаточно широких пределах характерна не только для правильного паузирования, но и для всего комплекса просодических характеристик.
Остается заметить, что в большинстве случаев отсутствие интонационной границы там, где она должна находиться, дает эффект быстрого и/или монотонного произнесения, а постановка ее в месте, где ее быть не должно, вызывает затруднения в понимании за счет специфического перцептивного эффекта - слушающему кажется, что говорящий (система синтеза) задыхается [Клатт 1987].
Что касается приписывания паузам категориальной длительности при синтезе речи, то длительность для границ абзацев может составлять 950 мс, для границ предложений 600 мс (средние значения, полученные в ходе предварительного эксперимента). Как показывают результаты исследований в области восприятия длительности пауз, длительность в 250-300 мс представляется нижней границей восприятия. Поэтому внутренние паузы должны иметь длительность не меньше 250 мс. Вопрос о том, существуют ли определяемые синтаксисом и семантикой иерархические различия по длительности внутри одного и того же синтаксического класса пауз (например, между паузами на границах предложений) и насколько необходимо передавать их при синтезе, ждет своего исследования.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Сб Фев 21 2009, 12:00 |
Сб Фев 21 2009, 12:00 | |
| Заключение: результаты, перспективыМы надеемся, что проведенный нами эксперимент и разработка специальной методики анкетирования и оценки нормативности разных интонационных прочтений, позволят лучше понять, что такое "произносительная норма в области интонации". Это важно не только для прикладных, но и общетеоретических задач в области фонетики. Однако методика нуждается в дальнейшей доработке: вопросы формирования анкеты должны в большей степени учитывать опыт других лингвистических экспериментов, а также исследовательских методик психологии и социологии, использующих анкетирование. При обработке данных анкетирования в будущем должны применяться методы статистического многофакторного анализа. Одновременно возможность выделения неправильных прочтений на фоне отвечающих допустимой норме дает возможность изучения паузального поведения говорящего, которое воспринимается слушающим как неправильное, но не вносит искажений в смысл воспринимаемого высказывания. Анализ таких прочтений может иметь большую важность для прояснения функционирования когнитивных и физиологических механизмов формирования и обработки информации, на текущий момент малоизученных. Что же касается собственно прикладных задач расстановки интонационных границ и их паузации при озвучивании текста синтезатором, самые перспективные решения в этой области сегодня базируются на статистических моделях, параметры которых просчитываются по аннотированной тексто-фонетической базе данных. Идеальным вариантом для учета многофакторной природы этого просодического феномена, является такая база данных, которая содержит информацию, статистически значимую по объему, а список учитываемых параметров по возможности расширен и включает все значимые факторы (смысловой, синтаксический, фонетический, пунктуационный). Литература- [Адамец 1966] Адамец П. Порядок слов в современном русском языке. Прага, 1966.
- [Балестри и др. 1993] Balestri M., Lazzaretto S., Salza P. L. and Sandri S. The CSELT System for Italian Text-To-Speech Synthesis // Proceedings of Eurospeech 93. – Berlin, 1993, pp. 2091-2094.
- [Баченко и Фитцпатрик 1990] Bachenko J., Fitzpatrick E. A Computational Grammar of Discourse-Neutral Prosodic Phrasing in English // Computational Linguistics, №16, September 1993, pp. 157-167.
- [Бомер и Диттман 1962] Boomer D. S., Dittman A. T. Hesitation Pauses and Juncture Pauses in Speech // Language and Speech, 1962, vol. 5, pt. 4, pp. 215-220.
- [Бриман и др. 1984] Brieman L., Friedamn J.H., Olsehn R.A., and Stone C.J. Classification and Regression Trees, Wadsworth & Brooks, Monterey, CA, 1984.
- [Вэнг и Хиршберг 1992] Wang, M., and Hirshberg, J. Predicting Intonational Boundaries Automatically form Text: The ATIS Domain // Proceedings of DARPA Speech and Natural Language Workshop, 1992, pp. 378-383.
- [Гвоздев 1949] Гвоздев А.Н. О фонологических средствах русского языка. – М., 1949.
- [Гольдман-Эйслер 1961] Goldman-Eisler F. The distribution of pause durations in speech // Language and Speech, vol. 4, №4, 1961.
- [Дозорец 1971] Дозорец Ж.А. Эксперимент по определению связи между ритмом дыхания и паузами в речи // Ученые записки МГПИ, №423, 1971.
- [Джелинек 1976] Jelinek F. Continuous Speech Recognition by Statistical Models // Proceedings of the IEEE, vol. 64, №4, 1976, pp. 532-556.
- [Джелинек 1991] Jelinek F. Up from trigrams! // Proceedings of Eurospeech 91, Genova, vol.3, pp. 1037-1040.
- [Жарков и др. 1995] Жарков И.В., Слободянюк С.Л., Светозарова Н.Д. Автоматический акцентно-интонационный транскриптор произвольного русского текста // Бюллетень фонетического фонда русского языка, 3/1995. – Бохум-СПб, 1995, с. 58-70.
- [Зиндер 1979] Зиндер Л.Р. Общая фонетика. М, 1979.
- [Каспарова 1965] Каспарова М. Г. О механизме речевой паузы. Сообщение II. Восприятие паузы при "непрерывном" звучании речи // Новые исследования в педагогических науках. – №3, 1965. – С. 154-155.
- [Каспарова 1971] Каспарова М. Г. О речевой паузе // Исследование языка и речи. Ученые записки МГПИИЯ им. М. Тореза. – №60. – М., 1971. – С. 146.
- [Келлер и др. 1993] Keller E., Zellinger B., Werner S., Blanchoud N. The Prediction of Prosodic Timing: Rules for Final Syllable Lengthening in French // Proceedings of the ESCA Workshop on Prosody. – Lund, 1993, pp. 212-215.
- [Кене и Кагер 1989] Quene H. and Kager R. Automatic Accentuation and Prosodic Phrasing for Dutch Text-To-Speech Conversion // Proceedings of Eurospeech 89, Paris, pp. 214-217.
- [Клатт 1987] Klatt D.H. Review of Text-To-Speech Conversion for English // Journal of Acoustic Society of America, Vol. 82, №3, 1987, pp. 737-793.
- [Кривнова 1995] Кривнова О.Ф. Перцептивная и смысловая значимость просодических швов в связном тексте // Проблемы фонетики II. – М., 1995. С. 228-238.
- [Кривнова 1998] Кривнова О.Ф. Автоматический синтез русской речи по произвольному тексту (2-я версия с женским голосом) // Труды международного семинара по компьютерной лингвистике и ее приложениям Диалог’98. – Таруса, 1998.
- [Ларченко 1990] Ларченко Г. Б. Пауза как просодическое средство смысловой выделенности в устной научной речи. Автореферат диссертации на соискание степени кандидата филологических наук. – Л., 1990.
- [Либерман и Черч 1992] Liberman M.J. and Church K.W. Text Analysis and Word Pronunciation in Text-To-Speech Synthesis // Advances in Speech Signal Processing, S. Furui, M.M. Sondhi eds. – Dekker, New-York, 1992, pp. 791-831.
- [Монаган 1990] Monaghan A. I. C. Rhythm and stress shift // Computer Speech and Language, №4, 1990, pp. 71-78
- [Ларрёр и др. 1989] Larreur D., Emerard F. and Marty F. Linguistic and Prosodic Processing for a Text-to-Speech Synthesis System // Proceedings of Eurospeech 89. – Paris, 1989, pp. 510-513.
- [Линдстрём и др. 1993] Lindström A., Ljungqvist M. and Gustafsonn K. A Modular Architecture Supporting Multiple Hypotheses for Conversion of Text to Phonetic and Linguistic entities // Proceedings of Eurospeech 93 – Berlin, 1993, pp. 1463-1466.
- [Лунгквист 1994] Ljungqvist M., Lindström A and Gustavson K. A New System for Text-to-Speech Conversion and it’s Application to Swedish // Proceedings of the International Conference on Spoken Language Processing 94. – Yokohama, 1994.
- [Мартин 1987] Martin P. Prosodic and Rhythmic Structures in French // Linguistics, №25, 1987, pp. 925-949.
- [Мертенс 1993a] Mertens P. Accentuation, Intonation et Morphosyntaxe // Travaux de Linguistique. – Katholieke Universiteit Leuven, №26, 1993, pp. 21-69
- [Мертенс 1993b] Mertens P. Intonational Grouping, Boundaries, and Syntactic Structure in French // Proceedings of the ESCA Workshop on Prosody. – Lund, 1993, pp. 156-159.
- [Николаева 1969] Николаева Т.М. Интонация сложного предложения в славянских языках. – М., 1969.
- [Николаева 1979] Николаева Т. М. О функциях пунктуационных знаков в русском языке // Современная русская пунктуация. – М., 1979. – С. 26-35.
- [Потапова, Блохина 1986] Потапова Р.К., Блохина Л.П. Средства фонетического членения речевого потока в немецком и русском языках. – М., 1986.
- [Розенталь 1994] Розенталь Д. Э. Справочник по правописанию, произношению, литературному редактированию. – М., 1994.
- [Сандерс и Тейлор 1995] Sanders, E., and Taylor, P. Using Statistical Models to Predict Phrase Boundaries for Speech Synthesis // Proc. Eurospeech’95. – Madrid, 1995, pp. 1811-1814.
- [Светозарова 1982] Светозарова Н. Д. Интонационная система русского языка. – Л., 1982.
- [Спроат и др. 1992] Sproat R.J., Hirshberg J., and Yarowski D. A Corpus-Based Synthesizer // Proceedings of the International Conference on Spoken Language Processing, Alberta, 1992, pp. 536-566.
- [Трабер 1993] Traber C. Syntactic Processing and Prosody Control in the SVOX TTS System for German // Proceedings of Eurospeech 93, vol 3. – Berlin, 1993, pp. 2099-2102.
- [Цеплитис 1974] Цеплитис Л.К. Анализ речевой интонации. – Рига, 1974. – С. 67-82.
- [О’Шонесси 1990] O’Shaughnessy D. Relationships Between Syntax and Prosody for Speech Synthesis // Proceedings of the ESCA tutorial day on speech synthesis. – Autrans, 1990.
|
|
| | | | evilone_
Участник «online словари»
Сообщений : 859
Репутация : 317
| | evilone_ | :: Сб Фев 21 2009, 13:21 |
Сб Фев 21 2009, 13:21 | |
| | mia Спасибо!!! |
|
| | | | groand
Наблюдатель
Сообщений : 2
Репутация : 0
| | groand | :: Чт Авг 13 2009, 11:58 |
Чт Авг 13 2009, 11:58 | |
| Очень много теории! А как быть со структурой текста! Произношение заголовков, подзаголовков, соответствующая интонация голоса и соответствующие паузы, а также после одинарных и двойных абзацев. Об этих элементарных настройках вообще никто не говорит и не спрашивает. Нельзя же весь текст читать просто смешивая всё в кашу. Выскажетесь, пожалуйста, по этому поводу!
Извините, но уже несколько дней с вашего сайта пытается загрузиться какой-то вирус. |
|
| | | | lev55
Участник «online словари»
Сообщений : 384
Репутация : 45
| | lev55 | :: Пт Авг 14 2009, 21:44 |
Пт Авг 14 2009, 21:44 | |
| groand
"Выскажетесь, пожалуйста, по этому поводу!"
Попробуйте сами ответить на поставленные вопросы, и сразу всё станет понятно
"для чего, как, зачем и почему".
"Об этих элементарных настройках вообще никто не говорит" - это не так!
Для разных движков свой подход - через словари, sampa и т.д., даже через реестр и Russian.rex (Ольга). Читайте остальные ветки сайта.
"уже несколько дней с вашего сайта пытается загрузиться какой-то вирус."
А до этого было иначе? ;-)
Это не вирус а Java. |
|
| | | | groand
Наблюдатель
Сообщений : 2
Репутация : 0
| | groand | :: Вс Авг 16 2009, 18:55 |
Вс Авг 16 2009, 18:55 | |
| Да, наверное это ява, но случайных посетителей сообщение антивируса наверняка отпугивает. Я очень много в интернете, и только с Вашим сайтом возникает такая проблема «с Явой».
Что касается настроек, то это вспомогательное средство (голос), например, для обработки собственных философских и литературных текстов (постоянно меняющихся и корректируемых) превращается в огромный труд, так что легче найти живого чтеца. Пользование должно быть простым, лёгким и воспроизведение точным. Но пока, как я вижу, придётся терпеть и браться за дальнейшее изучение этой темы. Как это серьёзные фирмы выпускают голоса, у которых на каждом шагу ошибки?! Или это не такие уж и серьёзные фирмы? |
|
| | | | evilone_
Участник «online словари»
Сообщений : 859
Репутация : 317
| | evilone_ | :: Пн Авг 17 2009, 00:08 |
Пн Авг 17 2009, 00:08 | |
| groand фирмы то серьезные но скорее всего просто цели применения совершенно другие. сейчас технологии чтения текста голосом используется не для озвучивания большого массива текста а скорее для озвучивания небольших фраз и предложений, произношение которых можно настроить так что будет произносить очень красиво, с паузами и нужной интонацией
тут где-то был обзор про применение технологий... там какие-то авто-системы, e-learning и прочие безобразия, нужно поискать |
|
| | | | | Паузирование при автоматическом синтезе речи | |
| | Паузирование при автоматическом синтезе речи |
|---|
| |