ВведениеПроблема адекватного разрешения неопределенностей, связанных с омонимией, играет суще-ственную роль в решении задач распознавания и синтеза речи. Наиболее важное значение эта проблема приобретает при решении задач преобразования «речь — текст» (распознавание речи), когда существенным является разрешение почти всех видов омонимии: синтаксической, грамматической, лексической, словообразовательной и фонетической (см. словарь лигвистических терминов [1]). Только один вид омонимии — графическая омонимия, не играет роли в решении задач распознавания речи. Зато этот единственный вид омонимов, называемых омографами, играет весьма существенную роль в задачах преобразования «текст — речь» (синтез речи). Игнорирование существования омографов нарушает смысловое восприятие синтезированной речи и дополнительно ухудшает её естественность. Нам не известно ни одной работы, направленной на анализ и решение проблемы адекватного разрешения неопределенностей при синтезе русской речи по тексту, связанных с существованием омографов. В данной работе мы попытаемся в какой-то степени заполнить этот пробел, опираясь на фактический материал, представленный в словаре омографов русского языка [2].
В русском языке существуют два источника графической омонимии: вариативность словесного ударения, местоположение которого в письменной речи не указывается (СУ-омографы), и письменная традиция не обязательного проставления необходимых точек на букве «Ё» («Ё»-омографы). Литера «Ё» была предложена княгиней Екатериной Дашковой в 1783 году, а в печати употреблена в 1795 году. Отдельной буквой она долгое время не считалась и в азбуку официально не входила. В русском языке буква «Ё» используется, чаще всего в тех позициях, где произношение [(j)o] образовалось из [(j)e], чем и объясняется производная от «Е» форма буквы, хотя с точки зрения фонетики логичней было бы поставить точки не над «Е», а над «О». Букве «Ё» — 225 лет. Хотя она родилась в Санкт Петербурге, однако 20 октября 2001 года в Ульяновске открылся единственный в мире памятник букве «Ё». Существует много различных мнений, как в пользу, так и против непременного использования буквы «Ё» в печатном тексте (см. http://www.yomaker.ru/). С нашей позиции — позиции разработчиков систем синтеза речи по тексту — отсутствие в тексте «Ё» влечёт за собой дополнительные трудности, которые должны быть разрешены в той или иной степени. Простейшее решение — игнорирование проблемы — влечёт за собой дополнительные трудности в восприятии синтезированной речи и к раздражающему слух Е-канию. Данная работа посвящена исследованию статистических закономерностей проявления «Ё»-омонимии в различных текстах, а также обсуждению вопросов разрешения связанных с ней неопределённостей.
Статистические характеристики омографических парСтатистические исследования проводились с использованием специально разработанной программы «HOMOGRAPH STATISTICS» и электронного словаря омографов, созданного на основе книжного словаря [2].
Целью исследования являлось определение статистической значимости «Ё»-омографов в общем списке «СУ»- и «Ё»-омографов [2], а также выявление особенностей статистических распределений только внутри подкласса «Ё»-омографов. Общее количество омографов, в соответствии с приведенными в [2] данными, составляет 3894 пар, из них «Ё»-омографов — только 232 пары.
Cтатистические характеристики определялись в отдельности для достаточно представительных и различных типов текстов:
•А. С. Пушкин — стихотворные произведения,
•Л. Н. Толстой — роман «Анна Каренина,
•Б. Акунин, Д. Рубина, Л. Петрушевская — современная проза,
•Труды конференции «ДИАЛОГ-2006» — научная проза.
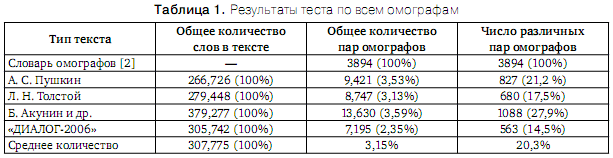
В таблице 1 приведены интегральные статистические характеристики этих текстов по всей совокупности омографов, содержащихся в словаре [2]. Как видно из таблицы 1, выбранные тексты различных жанров имеют примерно одинаковый объём, в среднем — около 300 тыс. слов. Средний процент вхождения омографов составил 3,15%. Если считать, что среднее число слов на странице равно 650, то около 20-ти слов могут оказаться омографами. В случае их неадекватного раскрытия, как показывает опыт, это приводит к весьма негативному впечатлению при прослушивании синтезированной речи. Из таблицы видно также, что наибольшее количество омографов встречается в современной прозе, а наименьшее — в научном тексте.
Очень интересный факт вытекает при рассмотрении 4-го столбца таблицы: всего только порядка 20% от общего многообразия всех омографических пар встречается в проанализированных текстах! Это указывает на первостепенную важность этого подмножества в решении задач разрешения омографии.
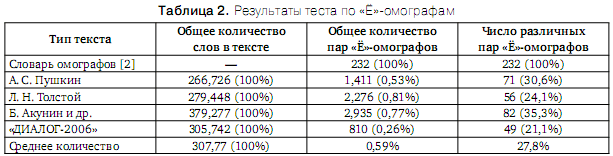
В таблице 2 приведены статистические характеристики 4-х классов текстов по совокупности пар «Ё»-омографов, содержащихся в словаре [2]. В сравнении с данными таблицы 1, средний процент вхождения «Ё»-омографов значительно ниже и составил 0,59%, что соответствует их общему количеству. Однако, если сравнить отношение количества всех пар омографов к количеству «Ё»-омографов: 3894/232=16,8 и соответствующее отношение процентов их вхождения в тексты: 3,15/0,59=5,3, то можно отметить более чем 5-ти кратную частотность «Ё»-омографов, а, следовательно, существенную важность разрешения этого вида омографии при синтезе речи.
Как и в случае таблицы 1, только порядка 30% от общего многообразия всех «Ё»-омографических пар встречается в проанализированных текстах.
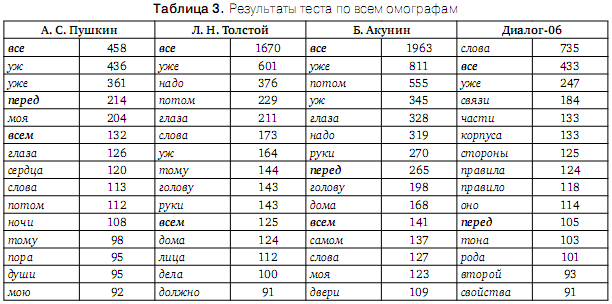
В таблице 3 приведены дифференциальные характеристики статистического анализа текстов по всей совокупности омографов (первые 15 наиболее частотных пар омографов), содержащихся в словаре [2]. Как видно из таблицы, во всех художественных текстах пара «Ё»-омографов слова «все» выдвинулась на 1-е место. В специфическом научном тексте «Диалог-06» омограф «все» уступил 1-е место, к нашему удовольствию, омографу «слова». Из таблицы видно также, что и некоторые другие «Ё»-омографы вошли в число наиболее частотных: «перед, всем».
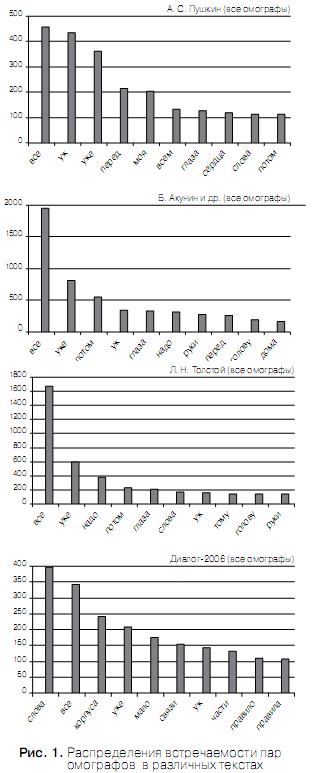
На рисунке 1 графически представлены распределения количества встречаемости в различных текстах 10-ти наиболее частотных пар омографов. Из рис. 1 видно, что пары омографов наиболее равномерно распределены (а, следовательно, наиболее информативны!) в стихотворных произведениях А.С. Пушкина и в научных трудах участников «ДИАЛОГа».
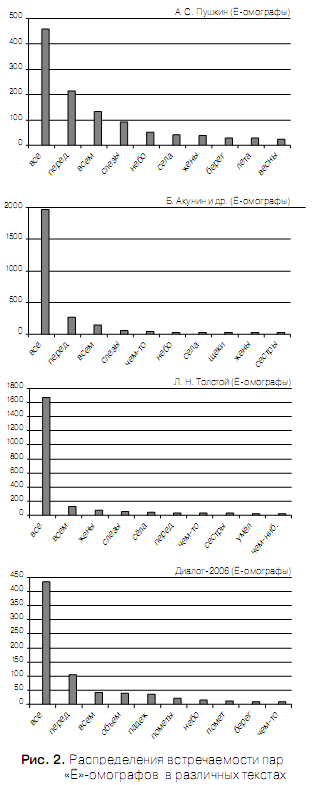
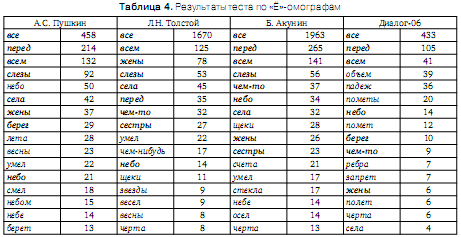
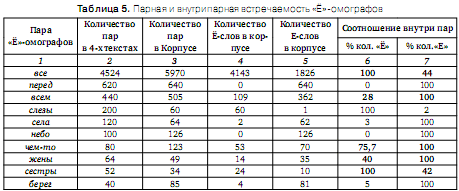
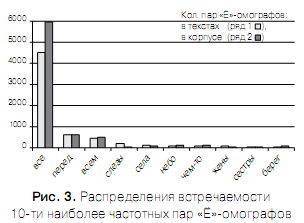
В таблице 4 приведены дифференциальные статистические характеристики текстов — первые 15 наиболее частотных пар «Ё»-омографов, содержащихся в словаре [2]. Как и ожидалось 1-е места во всех текстах заняла пара омографов «все».
Соответствующие таблице графические распределения представлены на рис. 2.2. распределений внутри пар «Ё»-омографов. Для определения статистических характеристик распределений внутри пар «Ё»-омографов использовались результаты описанного выше статистического анализа дифференциальных характеристик пар «Ё»-омографов и данные Интернет ресурса [3] «Поиск по акцентуированному корпусу».
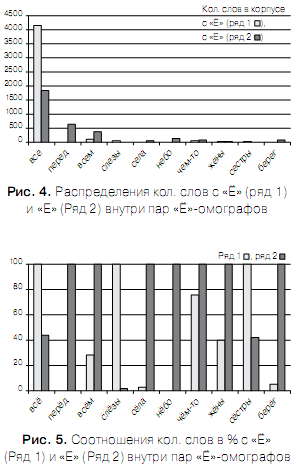
Вначале из таблицы 4 были отобраны 10 наиболее частотных пар «Ё»-омографов по всем рассмотренным выше 4-м текстам (помечены жирным шрифтом в табл. 4) и подсчитаны суммарные количества их встречаемости (см. столбец 2 таблицы 5 и рис.3). Затем для этих слов с помощью Интернет ресурса [3] в Корпусе текстов по драматургии, беллетристике, публицистике и научно-популярной литературе определены суммарные количества их встречаемости (см. столбец 3 таблицы 5 и рис. 3). В столбцах 4, 5 приведены результаты встречаемости в Корпусе [3] «Ё» и «Е» слов (см. также рис. 4), в столбцах 6, 7 — соотношение количества слов с «Ё» и «Е» в процентах внутри пар «Ё»-омографов (см. также рис. 5).
Некоторые правила разрешения «Ё»-омографической неопределённостиАнализируя результаты, приведенные в таблице 5 и на рис. 3 — 4, можно сделать следующие выводы. Как видно из табл. 5 (столбцы 2 и 3) использованная для статистического анализа выборка Текстов (А.С. Пушкин — стихотворные произведения, Л.Н. Толстой — роман «Анна Каренина, Борис Акунин, Дина Рубина, Людмила Петрушевская — современная проза, Труды конференции «ДИАЛОГ-2006» — научная проза) является достаточно представительной и сравнимой по объёму с Корпусом текстов по драматургии, беллетристике, публицистике и научно-популярной литературе, представленном в [3].Полученные распределения встречаемости 10-ти наиболее частотных пар «Ё»-омографов в изученных Текстах и в Корпусе в высокой степени подобны (см. рис. 3), что говорит о достаточной степени достоверности полученных данных. Из рис. 3 и 4 следует, что подавляющее количество «Ё»-омографов как в Текстах, так и в Корпусе приходится на пару омографов «ВСЕ», что подчёркивает исключительную важность нахождения правил их разрешения при синтезе речи. Из табл. 5 (столбцы 6, 7), а также из рис. 5 видно, что в 5-ти из 10-ти наиболее частотных пар «Ё»-омографов появление той или иной реализации омографа в паре более или менее равновероятно ( пары: ВСЁ_ВСЕ, ВСЁМ_ВСЕМ, ЧЁМ-ТО_ЧЕМ-ТО, ЖЁНЫ_ЖЕНЫ, СЁСТРЫ_СЕСТРЫ). В оставшихся 5-ти парах с высокой степенью достоверностью можно выбирать варианты: ПЕРЕД, СЛЁЗЫ, СЕЛА, НЕБО, БЕРЕГ. Для пар омографов: ВСЁМ_ВСЕМ, ЧЁМ-ТО_ЧЕМ-ТО, слова с «Ё» с высокой степенью достоверностью могут быть определены по наличию перед ними предлогов «о», «об» или «обо». Для пар омографов: ЖЁНЫ_ЖЕНЫ, СЁСТРЫ_СЕСТРЫ, слова с «Ё» могут быть определены по их принадлежности к существительным множественного числа. Наибольшую трудность представляет разрешение омографической неопределённости для слов ВСЁ_ВСЕ.
«ВСЁ» или «ВСЕ»? Для разрешения омографической неопределённости пары ВСЁ_ВСЕ можно использовать некоторые эмпирически найденные контекстуальные правила, работающие с достаточно высокой степенью достоверностью. Для этой цели был проведен выборочный анализ встречаемости слов ВСЁ и ВСЕ в сочетании с другими словами в романе Б. Акунина «Азазель», содержащего 55 тыс. слов. Было подсчитаны количество сочетаний слова ВСЁ с различными словами или знаками препинания при условии, что слово ВСЕ ни разу не встретилось в тех же сочетаниях. Получены следующие наиболее частотные сочетания этого вида:
•ВСЁ+Любой Знак Препинания — 24 раза
•ВСЁ+РАВНО — 21раз
•ВСЁ+ ЭТО — 11 раз
•ВСЁ+ТАК(ТОТ, ТЕМ) ЖЕ — 9 раз
•ВСЁ ВРЕМЯ — 5 раз
•ВСЁ ЕЩЁ — 4 раза
•ВСЁ БЫЛО — 3 раза
•ВСЁ МОЖЕТ — 3 раза.
Определено также около 30 других сочетаний такого рода, встретившихся от 1-го до 2-х раз в проанализированном тексте. Для более глубокого анализа возможностей разрешения омографической неопределённости пары ВСЁ_ВСЕ на том же тексте были проведены эксперименты с использованием синтаксического разбора предложений с использованием разработанной в Институте проблем передачи информации РАН системы ЭТАП-3, которая для каждого предложения строит синтаксическую структуру в виде дерева зависимостей [4].
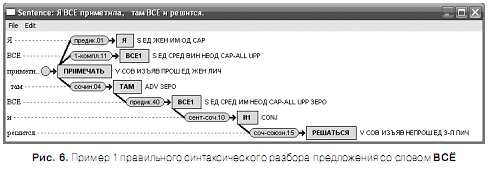
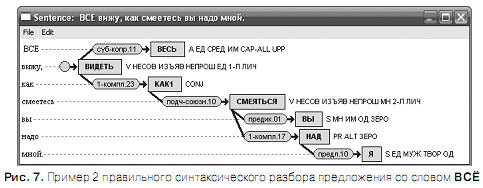
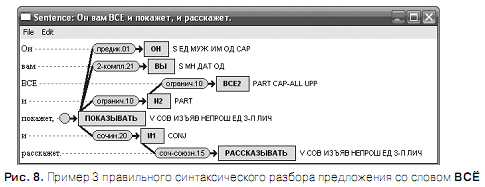
На рис. 6 — 8 приведены примеры правильного синтаксического разбора предложения со словом ВСЁ. При правильном разборе омограф ВСЁ маркируется либо как местоимение-существительное (S) единственного числа среднего рода (рис.6), либо как местоимение-прилагательное (А) единственного числа среднего рода (рис. 7), либо как частица (PART), играющая роль ограничителя ( рис. 8 ).
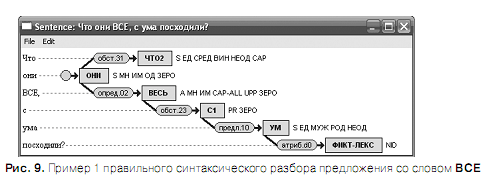
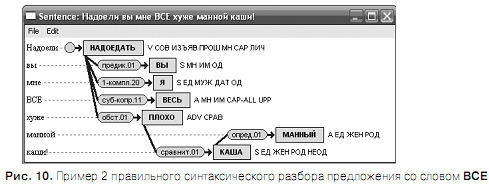
На рис. 9–10 приведены примеры правильного синтаксического разбора предложения со словом ВСЕ. При правильном разборе омограф ВСЕ маркируется всегда как местоимение-существительное множественного числа.
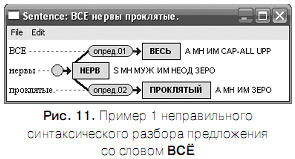
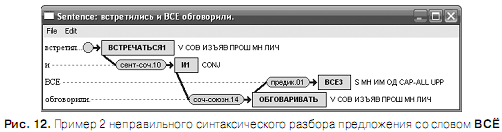
На рис. 11 и 12 приведены примеры неправильного синтаксического разбора предложения со словом ВСЁ. В этих примерах слово ВСЁ ошибочно распознано как ВСЕ , т.е. как местоимение-прилагательное (рис.11), либо как местоимение-существительное (рис.12) множественного числа.
В заключение заметим, что при использовании системы ЭТАП-3 на всём протестированном тексте (роман Б. Акунина «Азазель»), в котором присутствовало 123 вхождения омографа ВСЕ, обнаружено лишь 5 ошибочных отнесений слова ВСЁ к слову ВСЕ, т.е. только 4% ошибочного распознавания!
ЗаключениеОднозначного ответа на вопрос, поставленный в качестве эпиграфа к этой статье, пока не существует. Однако, с уверенностью можно сказать, что полное алгоритмическое решение задачи расстановки недостающих точек над «Ё» наступит не ранее, чем в полной мере будут решены проблемы морфологического, синтаксического, семантического и прагматического анализа текстов.
Литература- Д. Э. Розенталь, М. А. Теленкова. Словарь-справочник лингвистических терминов // Изд. «Просвещение», М. 1976, 543 с.
- А. В. Венцов и др. Словарь омографов русского языка // Изд. СПбГУ, Санкт-Петербург, 2004, 160 с.
- Национальный корпус русского языка “Поиск по акцентуированному корпусу” // Интернет ресурс: http://www.narusco.ru
- И. М. Богуславский, Л. Л. Иомдин, Д. Р. Валеев, В. Г. Сизов. Синтаксический анализатор системы ЭТАП и его оценка с помощью глубоко размеченного корпуса русских текстов // Труды Международной конференции <Корпусная лингвистика — 2008>. СПб.: Санкт-Петербургский государственный университет, 2008. С. 56–74.