|
| Natural language processing review |  |
| |
| Автор | Сообщение | Natural language processing review |
|---|
mia
V.I.P.
Сообщений : 184
Репутация : 7
 |  mia mia | :: Вс Фев 22 2009, 19:45 |
Вс Фев 22 2009, 19:45 | |
| Natural language processing
Machine/Speech translation
Machine translation is always an important research field in natural language understanding. It is an indispensable tool for conquering the language obstruction faced in the web-based language learning system. The translation between English and Chinese should emphasize the problem of semantic preservation according to the features of machine translation under the network environment, so that it can provide high quality multi-language network information service for the Sino-US network language learners. Today’s best Chinese-English machine translation system accuracy level can reach about 70% for daily corpus. And people can understand the content approximately when the accuracy level is more than 80%. Since the content rendered in the Sino-US web-based language learning is for teenagers from 11 to 18, and this degree matches the level of 1 - 3 grade in primary school of native language, we can keep the translation accuracy (semantic preservation degree) more than 80% for the corpus, whose literal language is norm, topic is clear and content is simple, using today’s technology. Thus we can try to add the literal automatic translation function selectively and partly to the Sino-US web-based language learning system. The Sino-US web-based language learning software can be conductive to the function of literal translation between Chinese and English for the simple text which has clear topic and normal sentence type. However, the speech translation is collecting synthetical technology applications such as speech recognition, language understanding, literal translation, written language conversion, communication protocol, dialogue management and so on. Therefore the function of speech-to-speech translation between Chinese and English (which is more difficult than literal translation) can only be brought into long-term plan to enable the web-based language learning to communicate well.
Difficulty of machine translation:
The machine still fail to understand the language genuinely at present, and the sentence still cannot be classified in the deep semantic and conceptual layer. It cannot make the conceptual explanation and semantic understanding for sentences. These difficulties are due to many factors such as the complexity of target expressing, the diversity of mapping type, the disparity of mutual degree between all the factors in source expressing and so on. Since the mapping between information content and symbol is not corresponding one after another, and the symbolic combination meaning has a series of complicated features that are different from bit, such as polysemy, hierarchy (namely structuralization), randomness and vagueness etc, it is not enough by far to depend merely on traditional information and calculation theory. Thus we must build up the new theory to solve such problems. Translation between Chinese and English includes Chinese-English translation and English-Chinese translation, and the former is more difficult than the latter for Chinese lacks the outer morph mark and the formation of word or sentence depends on the word order and functional words but not on accidence. The formation from morpheme to word and that from phrase to sentence both use a set of common rule. Additionally, the Chinese verb does not have tense change. The auxiliary is one peculiar kind of word in Chinese and there are abundant measure words in Chinese.
Direct dialogue with a computer
Man-machine interaction is to bring machines and equipments that have the ability to process speech information into human speech interactive object, make them have the ability to listen, read and write like humans, understand and respond to the speech, and have no limitation to time or location in interactive ways. According to psychology researches, the whole expression of human social intercourse information=7% intonation + 38% voice + 55% emotional expression. One single speech signal carries different kinds of information such as tone signal, semantic meaning, grammar structure, sex, and the social status and mood of the speaker. The redundancy of speech signal is large. So the information of different types existing at one time enables us to understand the content of talk even in a blurry and noisy environment. As for the man-machine speech interactive system of the next generation, it should have a strong user model and a powerful dialogue model, from which we can improve the adaptive ability of communication with computer by abstracting the topic of dialogue to process its content, to meet the needs for high quality of sentence understanding. To enhance the self-adaptive ability for the topic of dialogue, we divide dialogue rules into 3 types, namely general rules, rules relying on the topic and rules relying on the assignment.
Speech understanding
The speech signal has the vagueness of character order and this is mainly showed in acoustics decoding layer and word paragraphing layer. The course of language understanding itself is to intervene and solve this kind of vagueness. Speech understanding is to define the upper level process in natural language meaning of tone and to achieve the acceptive recognition rate, making use of linguistics, lexics, syntactic, semantics and pragmatics knowledge on the first floor foundation of tone recognition.
Man-machine speech interaction
Firstly, Humans obtain the initialized information through acoustic system (hearing some talks and then attaining the information of background knowledge and context) in practical interaction. Secondly, human brains will drive the language generating function to conduct the natural language forecasting formation after receiving the initialized information (heuristic information). Later on in the course of receiving speech information stream constantly, human ears compare the recognition results with the language generating ones in the agency of human brain, and the compared feedback information will return to human brain then. On the one hand, it will command the recognition module to be in favor of speech recognition in the self-adapted language environment. On the other hand, the information that feeds back to human brain can guide to carry on a new language generative process. Consequently, man-machine interaction should build up a speech recognition model with multilevel information feedback referring to the course of how humans understand natural language. Speech understanding abstracts the recognized candidate words. Statistical information base predicts the next sentence by adopting the method that combines the statistical reasoning with syntactical rules. Since the syntactical rules base can reduce the recognition mistakes in the acoustic layer and the number of candidate words, we’ll access sentence recognition by comparing information feedback, correcting errors and leading the successive speech processing. Man-machine speech interaction is to band the speech recognition and synthesis as well as natural language understanding together, and convert the conception into the next sentence in dialogue by producing the prediction, then forecast corresponding vocabulary and syntax in order to reduce the speech perplexity. The information used is knowledge needed in solving problems, semantic knowledge in application domain, dialogue background, expertise and language hobbies of speakers, etc. The course of processing conversation between human and machine divides the natural speech recognition into the recognition of utterance situation (including dialogue situation, dialogue content, mentality state, emotion state, intention state and pragmatic receiving process) and interpretation of reflection/intuition as well as logic/inference (including the semantic developing structure, examples of language used, phrase structure, model based on semantic meaning, general pragmatics processing, associative memory and vocabulary explanation etc ). Then it will export the result by synthesizing the speech in natural dialog form. It’s necessary to establish the dialogue corpus for the research of various man-machine dialogues. It can be of great value for researches to analyze the syntactic and semantic errors through designing and creating the dialogue corpus, selecting mission domain, collecting recorded traditions and dialogue situations. Today’s relatively sophisticated man-machine interactive systems are all in topic-limited domains, such as the booking-ticket automatic question-and-answer system in airport, the tourist automatic question-and-answer system, restaurant reservation automatic consulting system and so on. “Hotel reservation” is one example of man-machine interactive system. For example, a Chinese-English automatic translation system of institute of automation, CSA, for spoken language in the relevant area. It is through collecting, arranging and summarizing various sentence modes and locution used frequently when reserving hotel in daily life on the base of completely practical investigation and research, and fully considering the characteristics of spoken dialogue that finally formatting the spoken language translation system which has a wide rage comprehension, active sentence type and conforms to the spoken language custom. The vocabulary of this system is about 10,000 words, and the number of sentence types is up to 200 or more. It can achieve the recognition and translation of dialogue commonly used in each aspect of hotel reservation.
Computer should avoid the vicious circle when coming across problems in speech recognition due to the difference of cultures, language levels and environments for these non-native language teenage users. It should give corresponsive prompts through the speech synthesis in time to solve the problem successfully. On the foundation of speech recognition, we can predict and convert the next new topic according to the topic of the former sentence with the help of knowledge base in way of abstracting topic words changed in sentence. We can also improve the correct recognition rate by catching the outline of analyzed sentence effectively and utilizing natural language post-processing. The speech interaction should have the natural language statement generation mechanism with the ability of language understanding. Making use of speech synthesis, it can help users get through tough time and learn language well via web-based language learning. Owing to some factors such as culture and language level of users, the oral speech adaptation of non-native language is the first problem that should be solved in the acoustics layer of man-machine information interaction. It is very useful for correcting users’ pronunciation that today’s speech processing technology can easily find those words or phrases pronounced incorrectly. The man-machine speech interaction is an indispensable part in a web-based language learning system.
Human-Computer Interaction with Multimedia
(During the course of human-computer Interaction, if you don’t face the simplex text but a human visualization who can talk to you, you will feel the computer interface is more friendly and it is more convenient when you communicate with the computer. From people’s apperception and perceiving model, the research of the theories, methods and realizations for the intellectual human-computer interaction (include character, voice, face expression, gesture and other functions) is based on the difference of culture and psychology between Chinese people and American people). At present time, it is easy to animate a face to express the human’s averseness, anger, sadness, fearless, astonishment and happiness. It initially recognizes and then comprehends the user’s simple voice, expression and gestures. What’s more it can make imitation. It is the Object-Oriented pattern recognition that takes full advantage of multi-information handling ability and character to form an integration of Automatic speech recognition, Comprehension and Speech synthesis, Image analysis and Computer visualization, Diagram Comprehension, or even Recognized word and Page Comprehension. With the attempt to form the text-to-visual speech conversion from voice, text and image, it would make the human-computer interaction more hail-fellow and harmonious through making people see a human’s face when they are talking with computer. Visual speech can transmit the meaning people expressed at a certain extent and help people grasp this language. According to the research, as the voice information is given under a noisy environment or the listener has a lack of listening, a ‘talking head’ would be a great assistant for people to understand the voice. In the future, the Web-based language educational system will be a multimedia system made up of language recognition, speech recognition for multi-language, OCR, handwriting recognition and keyboard which act as the input system. On the other hand, we have high natural multi-language speech synthesis or texts as output system. Comminuting easily with people through the Internet, users would be more effective for the development of human beings and society.
The directly conversion of paragraph written-spoken, spoken-written
Natural Language is ever changing, when people carry on the exchange with the natural spoken language, many spoken languages they speak don’t conform to the rule; moreover along with time passing, the knowledge, the content and the meaning which language itself contains all can change and develop. Compared with the collection of the written language materials, it is much more difficult to collect spoken language materials. Although it is not that difficult to collect materials like movie scripts, play scripts, cahiers, cases of courts, visual broadcast, answers in the press conference and so on they are processed languages (accurate spoken language) which inevitably has certain artificial traces and cannot completely reflect the nature and essence of the natural conversations. The Chinese language materials were mostly collected from text language materials such as the publications, books. The language institution of China Academy of Social Sciences developed Chinese spoken corpus which numbered 30 million including the verbal parts and the corresponding recording parts. The British Natural Corpus (BNC) for English-speaking countries has a ten-million-word scale, 10% come from the spoken language resources. The International Corpus of English (ICE) is constructed by University of London and the language materials are taken from all English-speaking countries among which each component corpus contains one million words. And 60% are the spoken language materials, 40% are the written language materials. The authors and speakers of the texts are aged 18 or over, were educated through the medium of English, whose native language is English. But there are rare researches about the spoken language materials corpus for the 11-18 adolescents whose native tongues are English or Chinese. And there are more difficult to establish the non-native tongue spoken language corpus for adolescents. The construction of spoken language corpus is a must to each kind of human-machine conversation, and great contribution to the design and the creation of the dialogue corpus, the selection of recording convention, the dialogue scene collection, morbid analysis of the syntax and semantic question of the spoken language. On the foundation of the spoken corpus which is changed into written language corpus by some kind of process, it can provide the conditions for the transformation between spoken language and written language through the use of machine-translation in language materials Corpus, and so on illustrative sentence translation.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Вс Фев 22 2009, 19:45 |
Вс Фев 22 2009, 19:45 | |
| Exercise and evaluation of natural language generation (writing & speaking)
The generation of natural languages intends to make computers possess the ability of different types of expressions such as writing and speaking, which means a computer can automatically construct a natural language to according to any given theme by linguistic standard. Therefore, it is necessary to explore the process of cognition and probe related subjects to make the process of natural language generation of a computer correspond to that of human brain. In this process, a computer releases a series of stored sentences to assemble paragraphs and texts valid in communication. Then the programming system will generate an interior description that conforms to semantic and grammatical standard and the understandable natural language output. Natural language generation is the start of human-machine conversation in a given theme (a given situation), based on the formalized semantic data or logic formula. There is no standard that place the language input to the related linguistic items, which means semantic expressions and linguistic items are not directly related and they are combined by grammars. In the generation process, it is necessary to provide linguistic standard and specific description. For instance, the process has to select a term and its case in a given situation, which greatly relies on linguistic language. In this process, it is important to select the best term from the available and output it according to the request. This process transforms the unformed information into constructed, layered, and understandable information, which could become the knowledge of making prediction and policy. The generated language is required to be natural in vocabulary, grammar and semantics. The stimulus of the generation is the theme. The process is usually bound to a given theme to generate the character string of natural language based on the database. In the condition of clear concept, specific theme and standard content, it is possible to build the database of the theme and generate simple exercises for beginners pursing a foreign language under the current technology. However, this kind of generation cannot reach the ability of human writing. We can only pursue the optimized item.
Multilingual Speech-to-Speech Translation
Speech-to-speech translation takes speech processing a step further towards a speech-only communication interface. It incorporates speech recognition, natural language processing, translation, and speech synthesis, enabling computing devices to first recognize spoken language, then analyze the utterance through natural language processing, translate it into another language, and finally generate and utter a response through synthesized speech. Pioneering work in speech to speech technology has been done at Carnegie Mellon University beginning in the 1980's through Project JANUS. It operates on a number of limited domains such as appointment scheduling, hotel reservation, or travel planning. The JANUS project is aiming to make human-to-human communication across language barriers easier. Unlike a human interpreter, JANUS can also access databases to automatically provide additional information to the user. All systems are designed to work without a conventional keyboard. Whenever speech input is insufficient, other modalities such as handwriting and gesture recognition can be used to create a user friendly interface. To provide translation for conversational speech, the system has to handle fragmentary, errorful and disfluent language and heavily coarticulated and noisy speech. Instead of literal translation it has to provide useful interpretation of a user's intent. JANUS is used as CMU's system in the CSTAR-II consortium, where a number of international partners develop speech translation between English, Chinese, Spanish, French, German, Italian, Japanese, and Korean.
Several prototype applications have been developed through JANUS including a stationary video-conferencing to translate for a traveler booking a trip with a local travel agent and a mobile interactive linguistic assistant. The first one allows two users to communicate in a given domain via a videoconferencing connection. Each party sees the other conversant, hears his/her original voice and sees/hears translation of what he/she says as subtitles, captions and/or synthetic speech. The situation is cooperative, that is, both users want to understand each other and collaborate via the system to achieve understanding. The station accepts spoken input and produces a paraphrase of the input sentence and send a translation of this intended meaning to the other site in the desired language. If the paraphrase indicates that the system did not properly understand the intended meaning, the user activates a 'cancel' button to revoke the translation. Various interactive correction mechanisms facilitate quick recovery, should possible processing errors and miscommunications have altered the intended meaning. For more information see http://www.is.cs.cmu.edu/js.
Technology of Speech Synthesis
The TTS (Text-to-Speech) speech synthesis module is the component that generates the audible output of a system. According to the model used for speech generation, speech synthesis can be classified into three types, the formant synthesis, the concatenative synthesis, and the articulatory synthesis. The formant synthesis is the most commonly used method over the last decades and is based on the modeling of the resonances in the vocal tract. The concatenative synthesis is recently becoming more popular and is based on concatenating prerecorded samples from natural speech. In order to allow more flexibility in concatenative synthesis, a number of prosody modification techniques are usually applied. Probably the most accurate but also most difficult approach is the articulatory synthesis which models the human speech production system directly. Speech synthesis can also be classified into synthesis by rule and data-driven synthesis according to the degree of manual intervention. Formant synthesis have traditionally used synthesis by rule, concatenative synthesis belongs to the data-driven category.
Speech synthesis technology used on PC has improved a lot gradually and the synthesis effect is more and more natural. There has been a system that supports reading blended Chinese and English, which can provide the same Chinese tamber for the stock English words (about 10000 words) and read other English content using English engine compatible with Microsoft SAPI. The actual speech synthesis development kit provides the complete and standard interface function that can make users do the second development easily and conveniently. It can also establish the client proxy mode, provide uniform network interface protocol and support the parallel operation of different operating system and multi-machine, so that it can meet the needs of enterprise senior users. It can combine the speech synthesis system with the speech synthesis server perfectly and deal with a lot of current requests. Speech synthesis technology developed by the Microsoft Asian research institute and employed in Microsoft’s office XP software and windows XP operating system has already made the computer speak relatively natural Chinese and English. The Virtual operator can take the place of the artificial operator to broadcast, read all kinds of electronic text and be embed into software such as WORD, PDF, IE and so on. It can also be employed in vocal proofreading, vocal electronic books, language teaching, vocal personal assistant, multimedia e-mail, blind reading machines, speech explore, speech secretary, intelligent conversation between computer and humans, instruction with mutual entertainment and intelligent man-machine interactive interface as well as various message service domains.
|
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Вс Фев 22 2009, 19:46 |
Вс Фев 22 2009, 19:46 | |
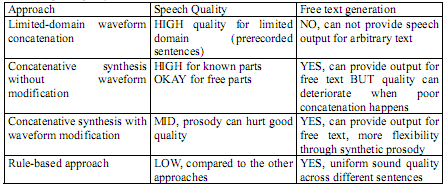
| Quality of Speech SynthesisThe most important attribute of speech synthesis is the intelligibility or quality of its output speech. Evaluations often consider just the quality of the best sentences and the percentage of sentences for which such quality is achieved, even though inferences from the quality of synthesized sound on one sentence to that of other sentences are not always reliable. The overall quality of the speech synthesis is a tradeoff between the quality of the system using the best sentences and quality variability across sentences. This can be described for the different families of speech generation approaches as follows: - Limited-domain waveform concatenation: this approach can generate very high quality speech for a given limited domain using only a small number of prerecorded segments. This approach is used in most interactive voice response systems. It would be suitable for the ELLS system as long as we do not expect the synthesis to deliver good quality on arbitrary texts.
- Concatenative synthesis with no waveform modification: Unlike the previous approach, these systems can synthesize speech from arbitrary text and can achieve good quality on a large set of sentences, but the quality can deteriorate drastically when poor concatenation happens.
- Concatenative systems with waveform modification: in these systems the waveform can be modified to allow for a better prosody match which gives these systems more flexibility. However, the synthetic prosody can hurt the overall quality which makes this approach questionable for second language learning acquisition in which very high quality synthesis is critical.
- Rule-based systems: These systems tend to give a more uniform sound quality across different sentences, but to the cost of an overall lower quality compared to the above described systems.
Table 8 summarizes the tradeoff between speech quality, domain limitations, and resource requirements for the different synthesis approaches.
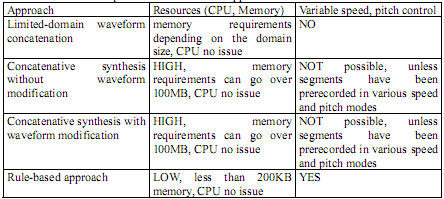
Table 8: Speech quality and domain limitations Other Attributes of Speech SynthesizerThe quality of the synthesized speech is possibly the most important attribute in a speech synthesis system, especially in the context of language learning, however other attributes are also interesting when integrating it into an end-to-end system. These other attributes are delay, memory resources, CPU resources, variable speed, pitch control, and voice characteristics. Delay or response time refers to the time it takes for the synthesizer to start speaking. The delay should be less than 200ms for interactive applications. Synthesizer vary considerably in terms of memory resources: Rule-based synthesizers require on average less than 200KB, concatenative systems can go over 100MB of storage. Therefore, if memory resources are critical, concatenative systems can cause problems. In contrast to memory, CPU resources are no big issues for synthesis. In the context of language learning the functionality of variable speaking speed can be very important and helpful. Variable speed this refers to the ability of a synthesis system to play portions of speech faster (to skim material) or slower (better intelligibility) in order to increase the learning effect. Concatenative systems can not accommodate this features unless a large number of segments are pre-recorded at different speeds. If the speech synthesizer system is required to output specific pitch like generating a voice of a song or varying pitch for tonal languages (like Chinese) then the functionality of pitch control is needed. Again, concatenative systems can not accommodate this feature, unless the speech segments had been pre-recorded at different pitch. Finally it might be desirable to change the voice characteristics of a synthesis system. This allows to provide specific voices such as robot like speech or different female and male characters. In the context of the ELL system this might be an issue in order to create a personal linguistic assistant or to create different characters in the game plot to interact with. This requirement is fulfilled by the flexible rule-based systems. Table 9 summarizes the resource requirements for the different synthesis approaches. Table 9: Resources requirements for different approaches Evaluation of Speech Synthesis TechnologyThe evaluation of synthesized speech is difficult since measuring the quality of speech is very difficult to do in an objective way. This has led to a large number of tests and methods to evaluate the different features of speech. Nowadays, speech synthesizers of various qualities are available as several different products for common languages. At present, several departments and organizations are expending speech synthesis technology market in USA, including Infovox, DecTalk, Bell Labs’ Text-to-Speech, Laureate, SoftVoice, CNET PSOLA, ORATOR, Eurovocs, L&H (now ScanSoft), Apple Plain talk, AcuVoice, CyberTalk, ETI Eloquent, Festival, ModelTalker, MBROLA, MS-Whistler, Neurotalker, Listen2, SPRUCE, HADIFIX, SVOX, SYNTE. Speech synthesis technology market in China, including Microsoft Research Asia, IBM Chinese Research Center, Intel Chinese Research Center, Motorola, Siemens, Dialogic, PHILIPS, L&H, Dragon, Lucent, ATR, Bell lab of AT&T, SinoVoice, SinoSonic, Infotalk, iFLYTEK and French CNET. And multi-language’s TTS has been used in public voice service of the telephone network. The speech synthesis technology in China is equal to that in western countries. The main R&D departments about TTS include the Department of Computer Science and Technology in Tsinghua University, University of Science & Technology of China, Institute of Acoustics in Chinese Academy of Sciences, Institute of Linguistics in Chinese Academy of Social Science, Taiwan Chiao Tung University, National Taiwan University etc. In the support of National 863 project, National Natural Science Fund Committee, Chinese Academy of Sciences, the research on Chinese TTS system has developed a lot. There are some successful instances such as KX-PSOLA (1993) from Institute of Acoustics in Chinese Academy of Sciences, their Lianxiangjiayin (1995), TH_SPEECH (1993) from Tsinghua University, KD863(1998) and KD2000 from University of Science & Technology of China. These systems are all using time-domain waveform appending technology based on PSOLA. Their understand ability and definition of Mandarin synthesis achieve a high level. Table 10 shows the overview of Chinese speech synthesis system in domestic and overseas areas. |
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Вс Фев 22 2009, 19:47 |
Вс Фев 22 2009, 19:47 | |
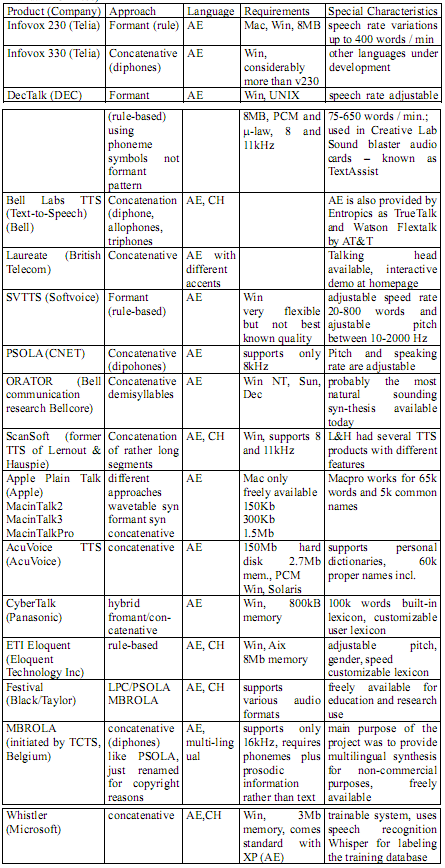
| Comparison of Speech Synthesis products (Focus: China)Microsoft Corporation (Dr. Chu Min)TTS technology developed by Microsoft Corporation is full grown on PC platform and it’s effect become more and more fluent. In this year, Microsoft Corporation bring to market a new Chinese-English compound TTS system which can keep the same voice when reading common English words (about 10000 words) and Chinese words. When reading English words, the System will use Microsoft SAPI compatible TTS engine. It is allowed to use proxy model on client and it affords a uniform network-interface protocol and supports multi-OS and parallel processing. The system can cooperate with speech synthesizing system and server, and can deal with a lot of requests at the same time. It can fit the need of all kinds of superior users in enterprise. Now the technology of speech synthesis developed by Microsoft Research Institute of Asia and adapted by Office XP and Windows XP can let PC speak natural Chinese and English. Virtual telephonist can replace artificial telephonist to broadcast and read e-documents. It can be embedded in WORD, PDF, IE etc. and can be used in fields such as speechproof, speech e-books, natural language teaching, speech personal assistant, multimedia email, reading machine for the blind, speech explorer, speech secretary, intellective dialog system, mutual entertainment teaching, intellective interface for interaction of human and machine, and all kinds of speech services. Beijing Jietong Huawen (Researcher Lu Shinan)The function of reading Chinese and English and transplant of natural speech synthesis technology have been realized in the system. Since the size of TTS library of the company is adjustable, so it is fit for various systems. In large-scale application systems like CTI, the speech library is about 2Gbytes with a high-and natural quality. Used in PC application, the TTS library can be condensed to 1.5~2Mbytes which may cause some damage and yet not so much as to ruin the sound quality for PC personal users. Used in the embedded operation systems and on-hand terminal application, the size of speech library is 1Mbytes. Dept. of Computer Science & Tech., Tsinghua UniversitySonic system: can be run in DOS, Windows and Unix operation systems. Its main function is: Transform the Chinese characters of the first and second level national standard to speech; Output Chinese characters, words, sentences, texts, punctuations, numbers and operators by means of speech; Speech out in the form of sentences, and make out the correct sound of multi-sound Chinese character automatically; Change the volume, pitch, speed, pause among words and sentences easily; Support functions of “Pause”, “Resume” and “Stop” buttons when outputting speech; Support DLL and can provide a series of API functions for TTS; Allow users to make TTS application programs as they wish. Till now the system has been used in many fields. In 2001, it applied to Beijing 168 sound communication station and provided subassembly products TTS gateway of VoicMail service system of a uniformed message platform (which applied to China Mobile uniformed message platform of Mobile Dream network). Huayi Speech Center, which was founded with the cooperation of Yanhuang NewStar Network Science and Technology Corporation, can let computers understand completely the inputted texts, let the synthesized sound express meanings correctly and let the voice sound more natural and pleasant by using methods of texts rearrangements, words separation, grammatical and semantic analysis, rhythm, acoustics and linguistics processing. China University of Science and TechnologyKD-863 Chinese Speech Synthesis System (1998), compared with the popular technology of PSOLA in the world, has its outstanding improvement in both sound quality of output speech and natural level. KD-863 uses a new way of sound synthesis based on speech database with its main idea of quantifying and combining the thousands of sound varieties of Chinese speech in actual sound stream, and designing a Chinese speech base-element library of multi-samples. The library contains the information of the rhythms change and only by choosing the base-element library samples during synthesis to realize the control of rhythms. At the same time the samples in the speech base-element library can be obtained directly from natural sound, the sound damage can be avoided by obtaining units of changing speech when using signal processing technology, and thus the synthesized sound is adjacent to the natural sound. KD-863 was applied to “114 automatic telephone broadcasting system” designed for ShenZhen Huawei Technology Company and “speech (fax) query system of enterprises” designed for National General Bureau of Commerce. KD-2000 Chinese TTS system uses layered structure to solve the processing of special symbols, words’ segmentation and combination effectively, which results in great improvement in the overall quality of Chinese TTS system. Now intellectual Chinese platform software “Free to speak 2000” with KD-2000 TTS as its kernel has been into market. For the mixed problems in the speech synthesis of combined languages of Chinese and English, Keda Xunfei Company has established a model for Text analysis system and rhythm rule for combined languages of Chinese and English and has made Xunfei speech synthesis system of Inter Phonic C&E rev 1.0. IBM Corporation (cooperate with Sanhui Company)Speech Library of Chinese characters: Every sound was pronounced by a real man or woman and the sound of all Chinese characters are recorded. It also provides an index table for second-level symbols’ inner-code and speech library offset. It can be used in simple TTS applications, such as the broadcasting of numbers, names of people, places, stocks and so on. It also provides C language programming exampling source code, and can be used in any kind of operation systems and speech cards. Chinese and English TTS Systems: It has a large word library and thus can recognize multi-sound characters and master the tones and rhythms of speaking correctly. Users can choose the sound made by real men or women and adjust the volume, speed and tone of speaking. It has a good sense of reality and the understandable degree is above 99%. It also applies well in the speech hints of IVR system, EMAIL system containing sound and large-scale news information promulgation. It supports all types of Sanhui speech cards and adopts customer/server structure to support multi-channel large-scale system. It is applied well in the following operation systems: Windows NT4.0, Windows’2000. The programming tools used are: VB, VC, BC, VF, PB, Delphi and so on, and it also provide plentiful program and source codes. Viavoice TelephoneyThe system provides users an open-style speech recognition engine and perfect environment for application development. Users can easily and conveniently integrate speech recognition functions in telephone systems to provide speech interaction interfaces for speech service systems, electronic business platforms and speech application systems concerned with telephone communications. The main characters are as follows: - Speech recognition engine use speech examples of practical telephone channel, and has a high recognition rate for continuous speech. It can be fit for the telephone noise channel of speaker independence.
- The telephone speech application system has a strong flexible. So it not only can be used in single-machine systems, but also can be extended to applications of large-scale multi-engine and multi-server enterprises.
- Speech synthesis is natural and clear, easy to understand.
- New words can be added by inputting speech, and can also be added dynamically to the word set when the system is under operation, and the ways of adding words can be flexible.
- The interface of C/C++ application programming is hardware independence, and can connect with speech recognition and synthesis engine easily.
ViaVoice speech-control software can let users write and send e-mails by means of speech, let the computer simulate people make sound by TTS and can also allow users to “hear” the email. |
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Вс Фев 22 2009, 19:47 |
Вс Фев 22 2009, 19:47 | |
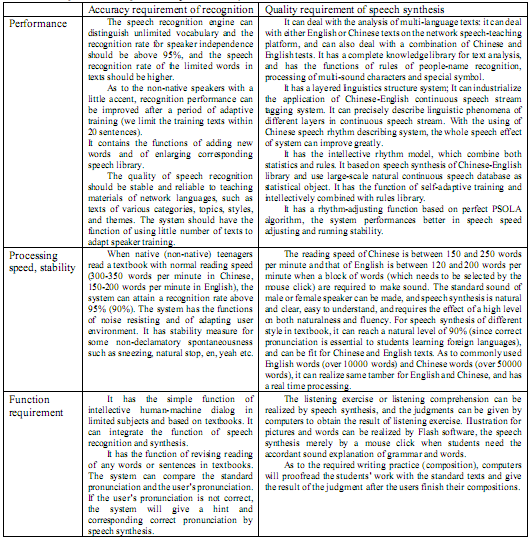
| Comparison of Speech Synthesis products (Focus: US)Table 11: Comparison of different Speech Synthesis products (AE = American English; CH = Mandarin Chinese) Expected OutcomeA recommendation of one or two speech recognition and synthesis systems that are judged appropriate for the E-language project based on the following dimensions: Table 12. Requirement of speech recognition and synthesis Table 13. Availability, cost, bandwidth Conclusion for the Application of Speech Synthesis systems in ELLSAlthough speech synthesis is a mature technology compared to speech recognition and speech translation, we cannot expect that available state-of-the-art synthesis quality is good enough for a large or unrestricted set of sentences. As can be seen from Tables 8 and 9, quality on a large variety of sentences comes at the cost of higher quality on a selected set of sentences. For those applications that require the flexibility of being able to produce acceptable output on a large, open set of sentences, a rule-based system might be the best choice. In the case of an ELL system, a rule-based system is suitable where an unrestricted input yields an audible output in the native language of the learner. Since the native student has high-level skills in his or her own language, s/he can tolerate the lower quality of produced speech without corrupting his or her language skills. But the ELL system also needs to provide audible output to the language learner in his non-native language. This output needs to be of very high quality without any imperfections in pronunciation or intonation. In this case the ELLS needs to rely on high quality for a limited number of sentences. This means favoring limited-domain waveform concatenation systems or even play back strategies for fixed phrases. Given the current state-of-the-art speech synthesis, we cannot get high quality synthesized speech for every sentence. Still, speech synthesis can make a significant contribution to the task of language learning by (1) playing back one's speech, by (2) exposing the learner to native or near-native speech, and finally by (3) creating a more engaging environment through the production of audible feedback. Table 12 and 13 summarize the criteria which are of concern in the context of ELLS. According to these criteria we can recommend the following Text-to-Speech modules that give feedback in the native language: these are Whistler from Microsoft (part of the Win XP operating system), ScanSoft TTS (for earlier Windows platforms), and Festival (for UNIX platforms). The systems are available in both American English and Mandarin Chinese. However the author cannot judge the intelligibility of the Chinese output and could not find any evaluation material in the western literature. Conclusion for the Application of Speech systems in ELLSFrom the rightmost column in Table 0, one might draw the conclusion that the speech engines from HTK, IBM, BBN, and AT&T are the best choices for the purpose of ELLS since they give the best performances overall. Unfortunately, these systems are not necessarily the best for every day applications, since they are tuned for giving highest performance in an offline running mode. Typical real-time factors in the SWB 2001 evaluation range from 234RT (BBN) on a Pentium-III 550 MHz to 540RT (IBM) on a SP1 power PC604e. These RT figures mean that the speech engine response time can be as long as 540 times the duration of the spoken utterance [Martin2001]. Real-time performance is a critical ELL system criterion. Many speech software systems have commercial spin-offs, such as Entropics, the spin-off from CU-HTK which was later bought out by Microsoft and probably influenced a MS speech product like Whisper. IBM has its commercial product ViaVoice, and Nuance is an early spin-off from SRI. There are no official benchmark tests available for these commercial products; however we think it is reasonable to assume that the technology of the research engine somehow reflects the technology included in the products. A further problem for evaluating an ELL system is in extrapolating current research results into the next generation. Furthermore, ELL systems are designed around the speech of children and adolescents and low proficiency non-native speakers. So far, NIST evaluation numbers are based on adult speech and no benchmark exists for non-native speech at all; in fact the research concerning accented speech of any kind is pretty new. In addition, there are uncontrollable environmental conditions, including varying microphone and channel quality, which complicate the evaluation of software packages for an ELLS. In order to find the most suitable speech engine it would be appropriate to determine the performance of selected systems on an ELL recognition task. We would need to create a benchmark test using real ELL data and decide on the basis of WER numbers. Unfortunately, such a procedure is very time consuming and not an option, given the tight time framework of the current project. Therefore, the best procedure for picking the most suitable system from the market is probably just to choose the best performing one on the basic of these less than ideally relevant WER numbers and consider buying the corresponding commercial versions, so long as other technological criteria are met. The author wants to emphasize here that she does not expect the commercial versions of any speech engine to give very good results. Rather, she thinks that additional adaptations will be needed to compensate for non-native children and adolescent speech. For these reasons it is her belief that a good ELLS system requires very close cooperation with the speech engine provider and needs its full support to improve the system. Therefore, it is utmost critical to chose a speech recognition provider that can ensure the full support over the period of the ELLS development and probably even beyond the distribution phase. References- Alvin Martin and Mark Przybocki: The 2001 NIST Evaluation for Recognition of Conversation Speech Over the Telephone. Presented at the 2001 NIST Hub-5 Evaluation Workshop, May 2001, Linthicum Heights, MA.
- Xuedong Huang, Alex Acero, Hsiao-Wuen Hon: Spoken Language Processing. Prentice Hall PTR, NJ, 2001
- http://www.speechstudio.com/commercial/speech.html
- Anon, In IBM VoiceType(TM) Developers Toolkit Version 3.0 for Windows’s 95 Programmer’s Guide. International Business Machines Corporation Publication. First Edition, Sep. 1996, USA.
- Kai-Fu Lee, Hsiao-Wuen Hon, Raj Reddy, An overview of the SPHINX speech recognition system. In IEEE Trans on Acoustic, Speech and Signal Processing, 1990, 38(1): 35-45.
- Chibelushi, Claude C.; Deravi, Farzin; Mason, John S.D. A review of speech-based bimodal recognition, IEEE Transactions on Multimedia v 4 n 1 March 2002. p 23-37.
- Min Zhou, Seiichi Nakagawa, Succeeding Word Prediction for Speech Recognition Based on Stochastic Language Model. IEICE Trans on Information and Systems, 1996, E79-D (4): 333-342.
- Pallett, David S. The role of the National Institute of Standards and Technology in DARPA's Broadcast News continuous speech recognition research program, Speech Communication v 37 n 1-2 May 2002 Elsevier Science B.V. p 3-14
- Cai Lianhong et al, Chinese metrical Learning and simulation in system for text to speech, Journal of Tsinghua University,98.4,Vol.38,P92-95 no.s1
- Tao Jianhua, Cai Lianhong,Zhao shijie, “Training research of metrical model in Chinese TTS systems”, Shengxue Xuebao/Acta Acustica
- Liu Jia, “Reviews for large vocabulary continuous Chinese speech recognition systems ",Tien Tzu Hsueh Pao/Acta Electronica Sinica,Vol. 28,No. 1,2000,Chinese Institute of Electronics, pp85-91
- Shan, Yi-Xiang; Zhang, Hao-Tian; Li, Hu-Sheng; et al, Implementation of a practical Chinese speech recognition system for the parcel post checking task Tien Tzu Hsueh Pao/Acta Electronica Sinica v 30 n 4 April 2002 Chinese Institute of Electronics p 544-547
- Wu, Ji; Wang, Zuoying, An efficient computation algorithm in Mandarin continuous speech recognition, Chinese Journal of Electronics v 11 n 1 January 2002, p 44-47
- Liu, Jia; Pan, Shengxi; Wang, Zuoying; et al, New robust telephone speech recognition algorithm with the multi-model structures, Chinese Journal of Electronics 9 2 2000 p 169-174
- Jedruszek, Jacek Speech recognition Alcatel Telecommunications Review 2 2000 Alsthom Publications p 129-134
- Furui, Sadaoki, Speech recognition - past, present, and future, NTT Review 7 2 Mar 1995 NTT p 13-18
- Lee, Chin-Hui; Rabiner, Lawrence R. Directions in automatic speech recognition, NTT Review 7 2 Mar 1995 NTT p 19-29
- Young, Steve, Review of large-vocabulary continuous-speech recognition, IEEE Signal Processing Magazine 13 5 Sep 1996 IEEE p 45-57
- Gruson, A.; Kelley, P.; Leprieult, Ph. Implementing speech recognition in intelligent networks, Alcatel Telecommunications Review 1st Quarter 1996 Alcatel Alsthom Publications p 48-52
- Lippmann, Richard P. Speech recognition by machines and humans, Speech Communication v 22 n 1 Jul 1997 Elsevier Sci B.V. p 1-15
- Goldsmith, John, Dealing with prosody in a text-to-speech system, International Journal of Speech Technology 3 1 1999
* E-language learning system (ELLS) |
|
| | | | mia
V.I.P.
Сообщений : 184
Репутация : 7
| | mia | :: Вс Фев 22 2009, 19:56 |
Вс Фев 22 2009, 19:56 | |
| | перевод на русский |
|
| | | | | Natural language processing review | |
| | Natural language processing review |
|---|
| |