Этот метод - основной и элементарный подход к созданию говорящего компьютера. В его основу положено предположение, что любое сложное речевое сообщение может быть получено путем простого соединения (компиляции) элементов речи.
Элементы речи (словарь) начитываются диктором, кодируются аналого-цифровым преобразователем (АЦП) и записываются в цифровом виде управляющей ЭВМ в постоянное запоминающее устройство (ПЗУ). При синтезе речевого сообщения закодированные речевые единицы считываются из ПЗУ в нужной последовательности с одновременным восстановлением речевого сигнала. Для восстановления речи можно использовать обратное преобразование с помощью цифроаналоговых преобразователей (ЦАП).
Очевидная простота этого метода позволила в короткий срок разработать большое количество компиляционных синтезаторов (США, Япония). Качество речи хорошее, для заранее подготовленного текста, однако попытки качественного синтеза произвольного текста путем простой компиляции слов, слогов не дали ожидаемых результатов. Стало ясно. что все элементы речи тесно связаны между собой внутри фразы. Речь, составленная из изолированно произнесенных элементов, звучит ненатурально, так как в этом случае отсутствует фразовое и синтагматическое ударение.
Кодирование формы речевых сигналов с использованием импульсно-кодовой модуляции (ИКМ).Форму сигнала можно кодировать с помощью ИКМ, разнообразных модификаций ИКМ, а также за счет представления формы речевого сигнала некоторой упрощенной функцией (например, прямоугольником, трапецией и т.п.).
Исходная информация о сигнале обычно поступает в виде последовательности отсчетов, взятых с некоторой частотой квантования fкв. Чем шире спектр сигнала, тем выше должна быть величина fкв. Согласно теореме Котельникова В.А., для того чтобы при квантовании не потерять информацию о высокочастотных составляющих сигнала, необходимо выполнить условие fкв 2 fв, где fв - верхняя граница спектра сигнала. Это соотношение верно при условии идеальной фильтрации восстановленной ступенчатой функции. Практически верхние частоты передаются со значительными искажениями, поэтому принимают fкв= (45)·fвили жертвуют точностью передачи высокочастотных компонент.
Структурная схема цифровой записи речи с помощью ИКМ показана на рис. 8.1.
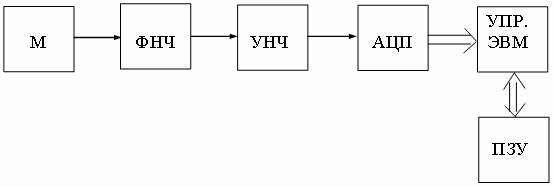
Рис. 8.1 - Цифровая запись речи с помощью ИКМ
Этот метод основан на цифровой записи аналоговых сигналов. Квантование сигнала речевого сообщения показано на рис. 8.2.
Аналоговый сигнал, полученный с микрофона М, содержит низкочастотные и высокочастотные составляющие. Этот сигнал пропускается через фильтр нижних частот (ФНЧ), что позволяет удалить из них составляющие с частотой, выше половины частоты выборки, затем усиливается до необходимого уровня усилителем низкой частоты (УНЧ). После усиления сигнал подается на АЦП.
Преобразование амплитудно-модулированного сигнала в ИКМ-сигнал показано на рис. 8.3.
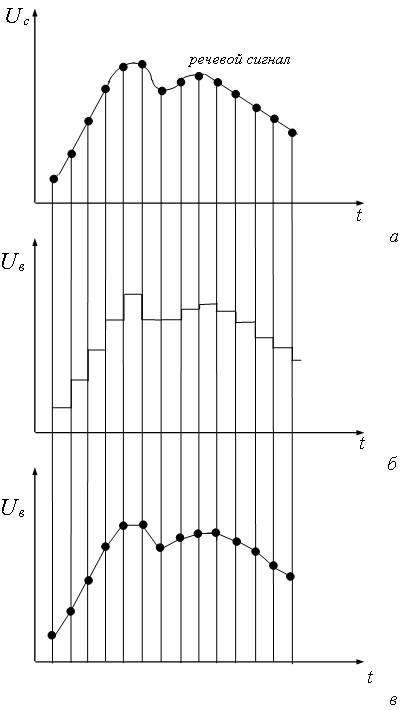
Рис. 8.2 - Квантование сигнала: а - взятие отсчетов; б - восстановление сигнала в виде ступенчатой функции; в - линейная аппроксимация
[center]
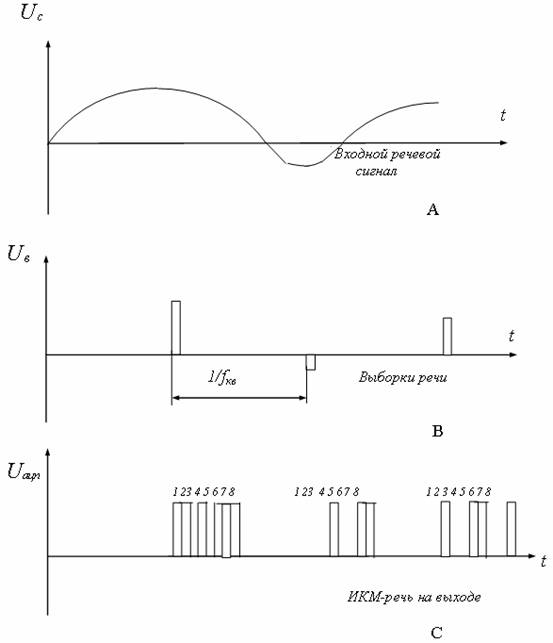
Рис. 8.3 - Преобразование амплитудно-модулированного сигнала в импульсно-кодовый
Последовательность импульсов выборки с частотой квантования fкв, промодулированных по амплитуде в соответствии с величиной аналогового сигнала, преобразуется в цифровую форму и в виде сигнала импульсно-кодовой модуляции поступает в управляющую ЭВМ. Эти данные, представляющие из себя цифровую запись амплитуд исходного речевого сигнала, записываются в постоянное запоминающее устройство (ПЗУ).
Для воспроизведения записанного сигнала можно использовать обратное преобразование с помощью цифроаналоговых преобразователей (ЦАП). При этом возникает специфическая погрешность ступенчатой аппроксимации (см. рис. 8.2, б).
Воспроизводящая часть схемы синтезатора показана на рис. 8.4.
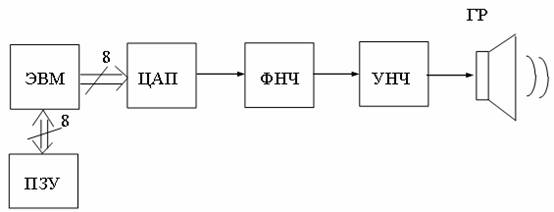
Рис. 8.4 - Упрощенная структурная схема синтезатора речи с ИКМ
Программа воспроизведения речи просматривает записанную ранее информацию и выводит ее побайтно на ЦАП. ЦАП должен быть совместим с входным АЦП по разрядности и частоте квантования fкв. Аналоговый сигнал с ЦАП поступает на ФНЧ, где отфильтровываются нежелательные высокочастотные компоненты, возникающие при восстановлении сигнала. Выходной сигнал с фильтра усиливается по мощности УНЧ и подается на громкоговоритель.
Средняя скорость передачи цифровой информации при ИКМ составляет 96 тысяч бит на 1 с речи. По существу, в методе непосредственного кодирования-восстановления, ЭВМ является устройством для записи речи, поэтому возможность сказать слово, которое не было заранее введено в память, здесь отсутствует. В подобных системах требуется мало аппаратных средств, качество синтезируемой речи хорошее. Однако есть серьезный недостаток - для хранения речевых сигналов в их непосредственной цифровой форме нужна память значительного объема. В тех случаях, когда необходимый словарь не слишком велик, данный метод наиболее экономичен в реализации.






