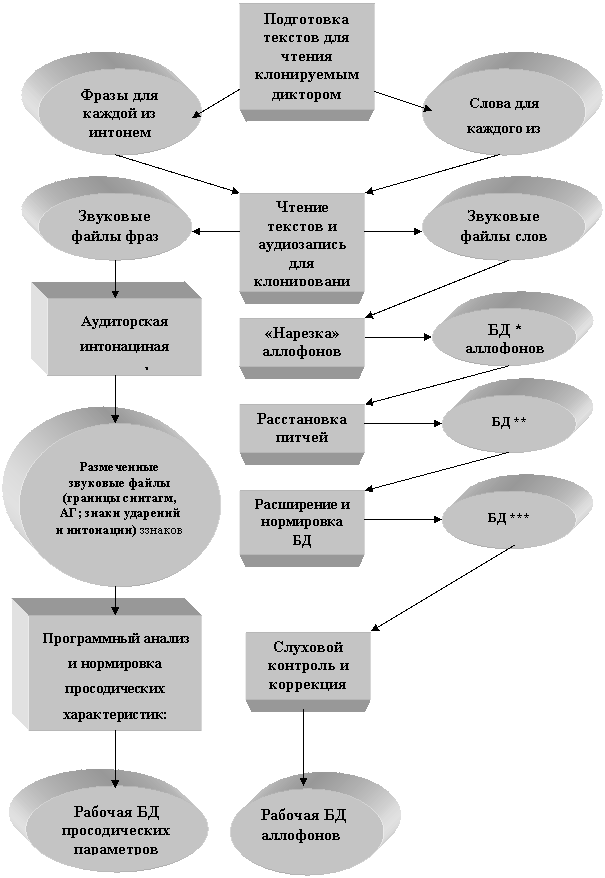
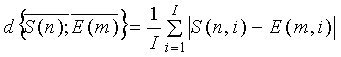Анализатор спектральных параметров речевого сигнала Для расчёта спектральных параметров могут быть использованы различные методы анализа РС, например, такие как FFT, LPC, кепстральный или формантный анализ. Наилучшие результаты клонирования фонетических и акустических характеристик речи получены при использовании синхронного с основным тоном FFT анализа.
Синхронный Фурье анализ обеспечивает максимальную устойчивость результатов анализа к изменениям частоты основного тона (ЧОТ). Этот факт наглядно поясняется на рис. 4, где для сравнения приведены спектры звука /А/, для трёх значений ЧОТ, полученные метдами синхронного и асинхронного анализа.

Рис. 4. Спектры звука /А/, для трёх значений ЧОТ: 100, 125, 145 Гц (сверху вниз)
ДП-с числения матрицы интегральных расстояний по рекуррентной формуле:
Процедура ДП-сравнения осуществляется путём вычисления матрицы интегральных расстояний по рекуррентной формуле:
Fn+1,m+1 = max[(Fn+1,m); (Fn,m+1); (Fnm + Qn+1,m+1)] (1)
при начальных условиях: Fn0 = F0m = 0.
В (1) Q - мера сходства определяется как: Q = 1/ exp q*[ d(m,n)],
расстояния между вектором реализации S(n) с отсчётами – n и вектором эталона E(m) с где d(n,m) – локальные отсчётами – m, q = (1,2,3,…) – экспериментальный параметр,
где i - номер спектрального параметра, I - число параметров.
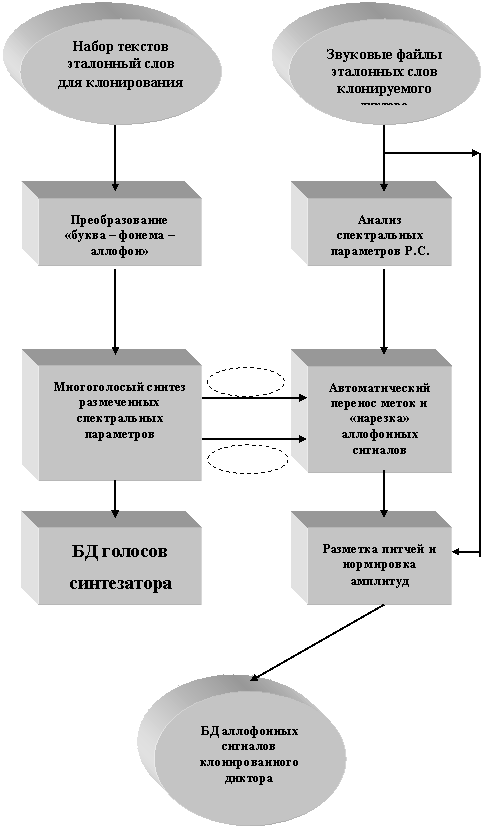
Процедура переноса меток Нелинейное сопоставление временных шкал 2-х речевых реализаций, одна из которых выступает в качестве эталонной (синтезированная последовательность спектров), осуществляется ДП-методом. Рис.5 поясняет процедуру нелинейного сопоставления 2-х реализаций разной длительности.
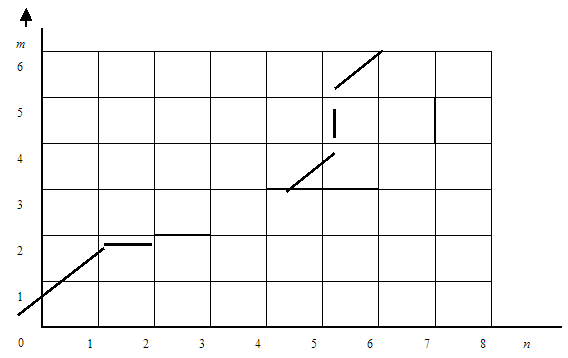
Рис 5. Графическая иллюстраци нелинейного поставления 2 речевых реализаций.
Для переноса меток аллофонов на матрице интегральных расстояний находится оптимальный путь соответствия реализации и размеченного синтезированного эталона, начиная с правого верхнего угла матрицы [M.N] по формуле:
n.in = Arg Max|(Fn-t,m); (Fn,m-1); (Fn-t,m-l + Qn-l;m-l)|.
Найденный путь ставит в соответсвие отсчёты {ш}меток аллофонов синтезированного эталона отсчётам {n} естественного (клонируемого) сигнала.
Разметка питчей и корректировка звуковой БДРазметка питчей речевого сигнала (PC) и корректировка осуществляется по следующему алгоритму.
Для всего аллофонного сигнала по ординате минимума сдвиговой функции (см. рис.6) определяем средний период основного тона ТО.
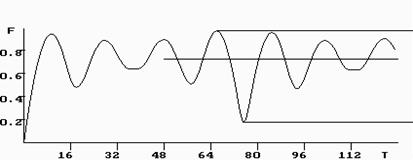
Рис 6. Сдвиговая функция РС
Находим начальную фазу - позицию питча в центре сигнала, от которого будут отсчитываться (влево и вправо) остальные питчи.
Для этого на середине сигнала берется окно размером в 3 периода ТО. В этом окне ищется участок с максимальным перепадом от положительной полуволны к отрицательной, т.е. такое место в окне, которое соответствует моменту времени закрытия голосовой щели и началу формантных колебаний.
Позицию питча определяет момент перехода через ноль от положительной полуволны к отрицательной.
1. Движемся вправо от центрального питча.
2. Берем окно размером в 3 периода ТО.
3. На нем определяется новый период основного тона ТО.
4. ТО ищется в диапазоне ТО (+)(-) 5% от ТО, полученное на предыдущей итерации.
5. Зная ТО, откладываем его от предыдущего питча и переходим туда.
6. Затем ищем ближайший момент времени перехода через ноль от положительной полуволны к отрицательной.
7. Ставим там питч и повторяем шаги 3-8
8. Когда дошли до конца сигнала -движемся влево от центрального питча по тому же алгоритму.
9. Полученные метки питчей переносим на исходный сигнал. Смотрим: если от первого питча до начала сигнала ТО/2 < t > 0, то этот участок сигнала выбрасывается. Та же процедура осуществляется для конца сигнала.
10. Начало и конец сигнала сглаживаются путем добавления слева и справа по 32 отсчёта и дополнения сигнала на этих отсчётах линейным участком от значения сигнала вначале (конце) сигнала до значения «0».
11. B соответствии с известной статистикой производится корректировка и нормировка амплитуд аллофонов.
Заключение. Компьютерное клонирование и его перспективыПроводимая нами на протяжении последних 3-х лет [1-5] аналогия между биологической проблемой клонирования и лингво-акустической проблемой синтеза персонализированной речи по тексту может стать не только лишь красивой метафорой. Во-первых, она подчёркивает общенаучную значимость, современность и сложность поставленной задачи. Во-вторых, она выделяет эту задачу в отдельный самостоятельный класс в ряду других задач современных речевых технологий. И, наконец, в-третьих, она стимулирует создание новых специализированных методик, а также автоматических и полуавтоматических методов "клонирования" персонального голоса и речи, одним из примеров которых является данная работа. В практическом плане разработка эффективной технологии клонирования голоса значительно повысит привлекательность использования синтезаторов речи в разнообразных компьютерных системах, в т.ч. в современных интеллектуальных системах корпоративного управления, благодаря высокому качеству и натуральности речи, её персонализации и узнаваемости голоса.
Литература- Лобанов Б.М. и др. Синтезатор персонализированной речи по тексту " Лобан оФон-2 000" Тр. Международной конференции, посвященной 100-летию российской экспериментальной фонетики. Ст.-Петербург, 2001, С.101-104.
- Лобанов Б.М. и др. Синтезатор речи по тексту как компьютерное средство "клонирования" персонального голоса. Тр. Международной конференции Диалог-2001, Москва, 2001, С. 265-272.
- Лобанов Б.М. и др. Проблемы предварительной обработки текста для синтеза украинской речи. Тр. Международной конференции Диалог-2001, Москва, 2001, С.57-63.
- Лобанов Б.М.. Проблемы и решения компьютерного "клонирования" персонального голоса и речи // Проблемы и методы экспериментально-фонетических исследований СПГУ. Ст.-Петербург, 2002. С. 301-308.
- Lobanov B.M., Karnevskaya H.B. TTS-Synthesizer as a Computer Means for Personal Voice "Cloning" ' Phonetics and its Applications Stuttgart: Steiner. 2002, P. 445-452.